


几行烂代码,用错 Transactional,赔了16万
注意:以下文章来源于why技术 ,作者why技术
前几天在某平台看到一个技术问题,很有意思啊。
涉及到的两个技术点,大家平时开发使用的也比较多,但是属于一个小细节,深挖下去,还是有点意思的。
来,先带你看一下问题是什么,同时给你解读一下这个问题
首先,这位同学给出了一个代码片段:

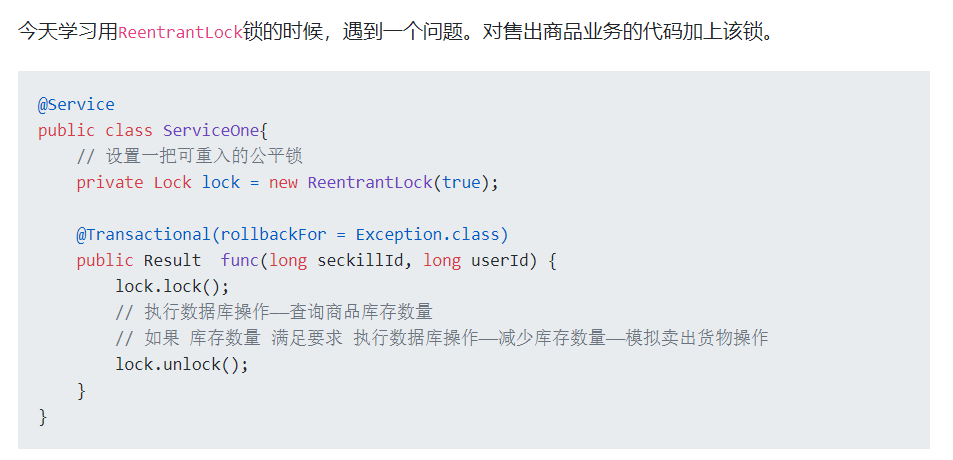
他说他有一个 func 方法,这个方法里面干了两件事:
- 1.先查询数据库里面的商品库存。
- 2.如果还有库存,那么对库存进行减一操作,模拟商品卖出。
对于第二件事,提问的同学其实写了两个操作在里面,所以我再细分一下:
- 2.1 对库存进行减一操作。
- 2.2 在订单表插入订单数据。
很显然,这两个操作都会对数据库进行操作,且应该是应该原子性的操作。
所以,在方法上加了一个 @Transactional 注解。
接着,为了解决并发访问的问题,他用 lock 把整个代码包裹了起来,保证在单体结构下,同一时刻只有一个请求能去执行减少库存,生成订单的操作。
非常的完美。
首先,先把大前提申明一下:MySQL 数据库的隔离机制使用的是可重复读级别。

这个时候,问题就来了。
如果是高并发的情况下,假设真的就有多个线程同时调用 func 方法。
要保证一定不能出现超卖的情况,那么就需要事务的开启与提交能完整的包裹在 lock 与 unlock之间。
显然事务的开启一定是在 lock 之后的。
故关键在于事务的提交是否一定在 unlock 之前?
如果事务的提交在 unlock 之前,没有问题。
因为事务已经提交了,代表库存一定减下来了,而这个时候锁还没释放,所以,其他线程也进不来。
画个简单的示意图如下:
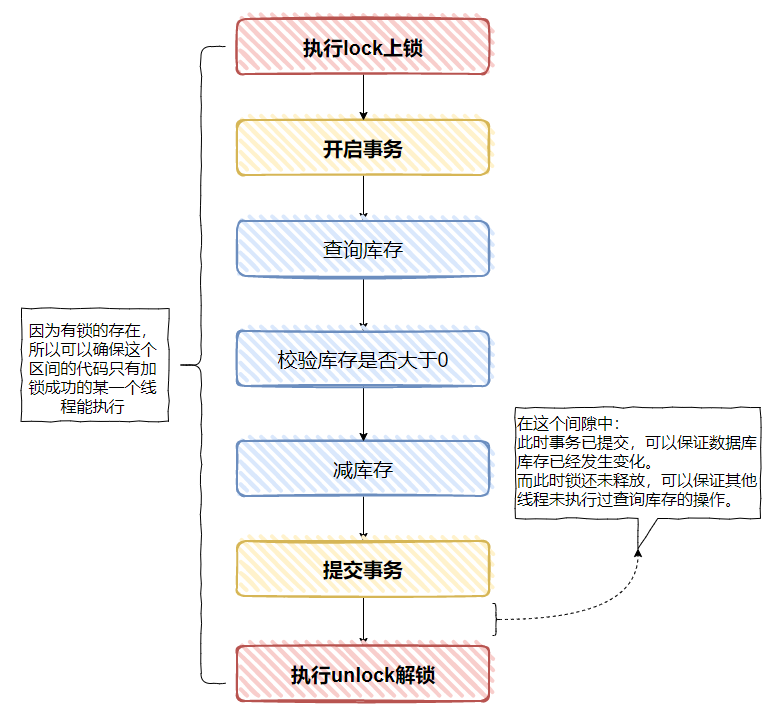
等 unlock 之后,再进来一个线程,执行查询数据库的操作,那么查询到的值一定是减去库存之后的值。
但是,如果事务的提交是在 unlock 之后,那么有意思的事情就出现了,你很有可能发生超卖的情况。
上面的图就变成了这样的了,注意最后两个步骤调换了:
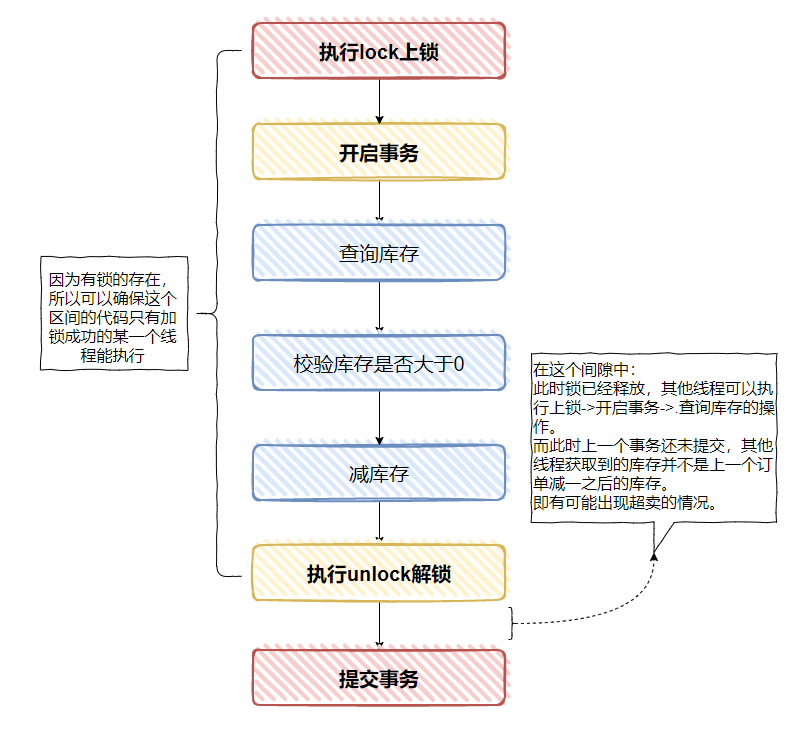
举个例子。
假设现在库存就只有一个了。
这个时候 A,B 两个线程来请求下单。
A 请求先拿到锁,然后查询出库存为一,可以下单,走了下单流程,把库存减为 0 了。
但是由于 A 先执行了 unlock 操作,释放了锁。
B 线程看到后马上就冲过来拿到了锁,并执行了查询库存的操作。
注意了,这个时候 A 线程还没来得及提交事务,所以 B 读取到的库存还是 1,如果程序没有做好控制,也走了下单流程。
哦豁,超卖了。
所以,再次重申问题:
在上面的示例代码的情况下,如果事务的提交在 unlock 之前,是没有问题的。但是如果在 unlock 之后是会有问题的。
那么事务的提交到底是在 unlock 之前还是之后呢?
这个事情,先把问题听懂了,接着我们先按下不表。你可以简单的思考一下。

我想先聊聊这句被我轻描淡写,一笔带过,你大概率没有注意到的话:
显然事务的开启一定是在 lock 之后的。
这句话,不是我说的,是提问的同学说的:

你有没有一丝丝疑问?
怎么就显然了?哪里就显然了?为什么不是一进入方法就开启事务了?
请给我证据。
来吧,瞅一眼证据。

事务开启时机
证据,我们需要去源码里面找。
另外,我不得不多说一句 Spring 在事务这块的源码写的非常的清晰易懂,看起来基本上没有什么障碍。
所以如果你不知道怎么去啃源码,那么事务这块源码,也许是你撕开源码的一个口子。
好了,不多说了,去找答案。
答案就藏在这个方法里面的:
org.springframework.jdbc.datasource.DataSourceTransactionManager#doBegin
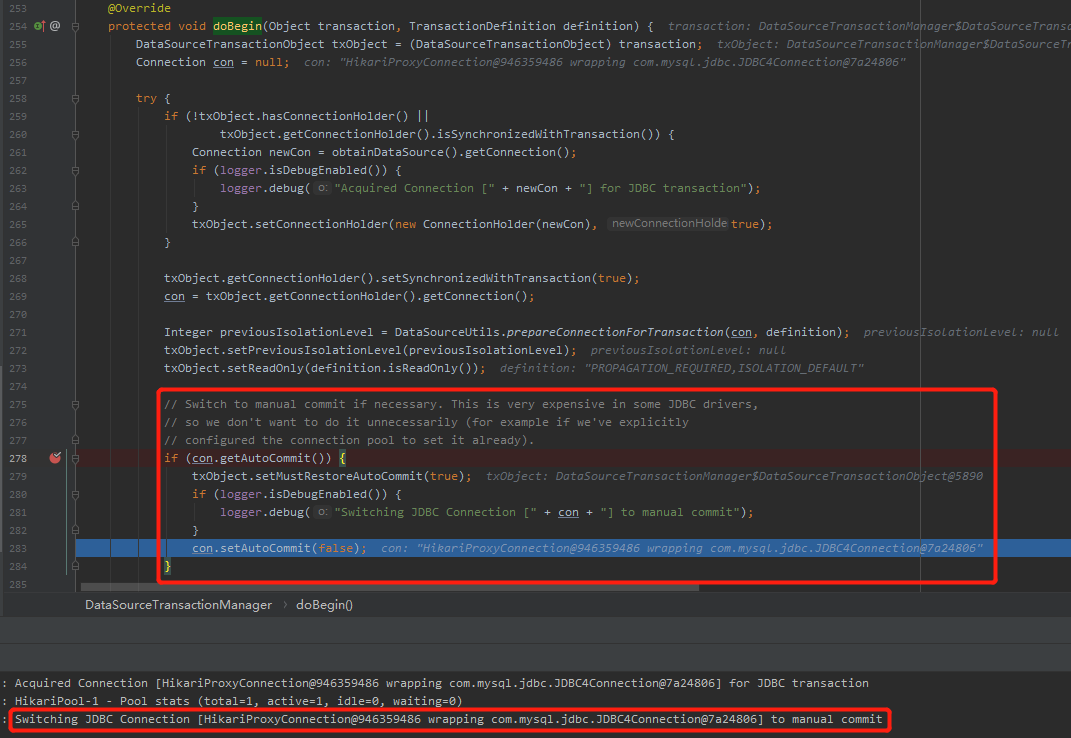
先看我下面框起来的那一行日志:
Switching JDBC Connection [HikariProxyConnection@946359486 wrapping com.mysql.jdbc.JDBC4Connection@7a24806] to manual commit
你知道的,我是个技术博主,偶尔教点单词。
Switching,转换。
Connection,链接。
manual commit,手动提交。
Switching … to …,把什么转换为什么。
没想到吧,这次学技术的同时不仅学了几个单词,还会了一个语法。

所以,上面那句话翻译过来就非常简单了:
把数据库连接切换为手动提交。
然后,我们看一下打印这行日志的代码逻辑,也就是被框起来的代码部分。
我单独拿出来:

逻辑非常清晰,就是把连接的 AutoCommit 参数从 ture 修改为 false。
那么现在问题就来了,这个时候,事务启动了吗?
我觉得没启动,只是就绪了而已。
启动和就绪还是有一点点差异的,就绪是启动之前的步骤。
那么事务的启动有哪些方式呢?
- 第一种:使用启动事务的语句,这种是显式的启动事务。比如 begin 或 start transaction 语句。与之配套的提交语句是 commit,回滚语句是 rollback。
- 第二种:autocommit 的值默认是 1,含义是事务的自动提交是开启的。如果我们执行 set autocommit=0,这个命令会将这个线程的自动提交关掉。意味着如果你只执行一个 select 语句,这个事务就启动了,而且并不会自动提交。这个事务持续存在直到你主动执行 commit 或 rollback 语句,或者断开连接。
很显然,在 Spring 里面采用的是第二种方式。
而上面的代码 con.setAutoCommit(false) 只是把这个链接的自动提交关掉。
事务真正启动的时机是什么时候呢?
前面说的 begin/start transaction 命令并不是一个事务的起点,在执行到它们之后的第一个操作 InnoDB 表的语句,事务才算是真正启动。
如果你想要马上启动一个事务,可以使用 start transaction with consistent snapshot 这个命令。需要注意的是这个命令在读已提交的隔离级别(RC)下是没意义的,和直接使用 start transaction 一个效果。
回到在前面的问题:什么时候才会执行第一个 SQL 语句?
就是在 lock 代码之后。
所以,显然事务的开启一定是在 lock 之后的。
这一个简单的“显然”,先给大家铺垫一下。
接下来,给大家上个动图看一眼,更加直观。
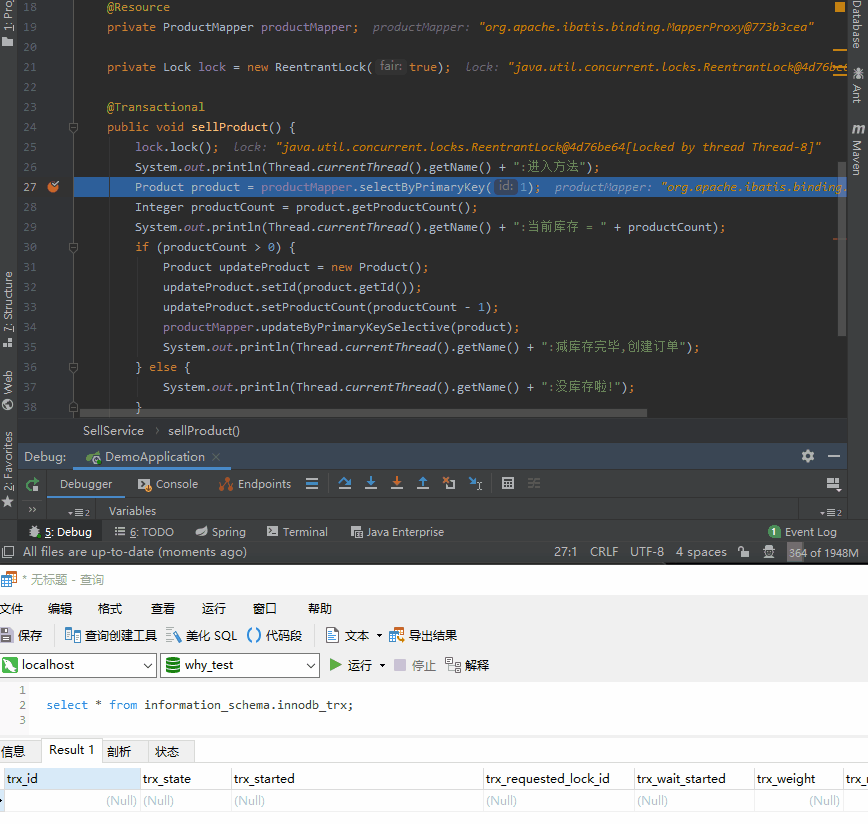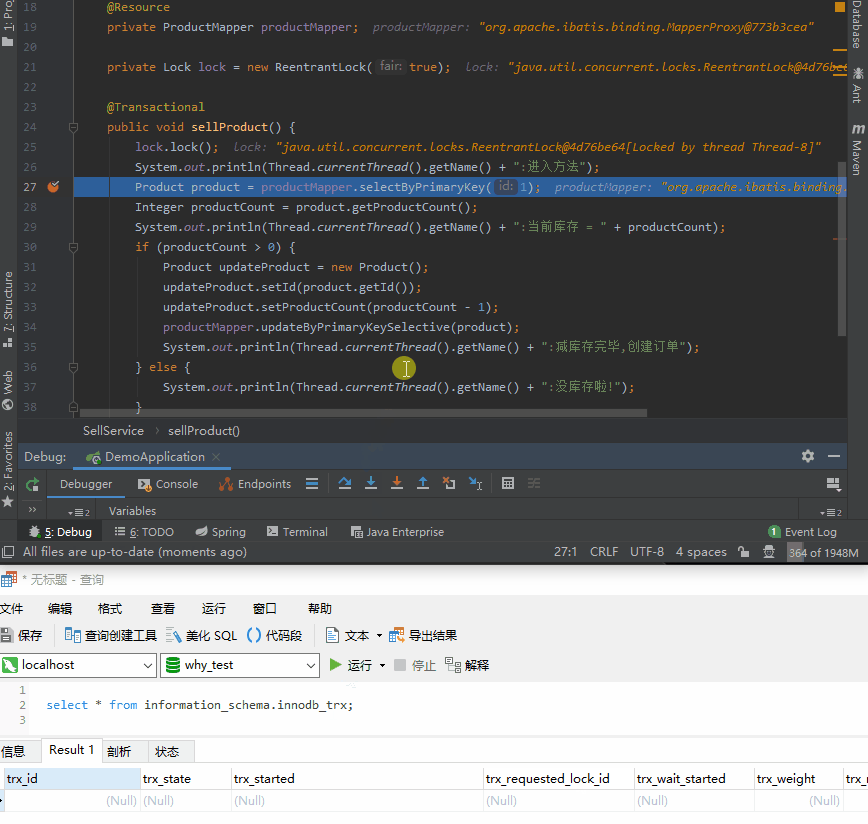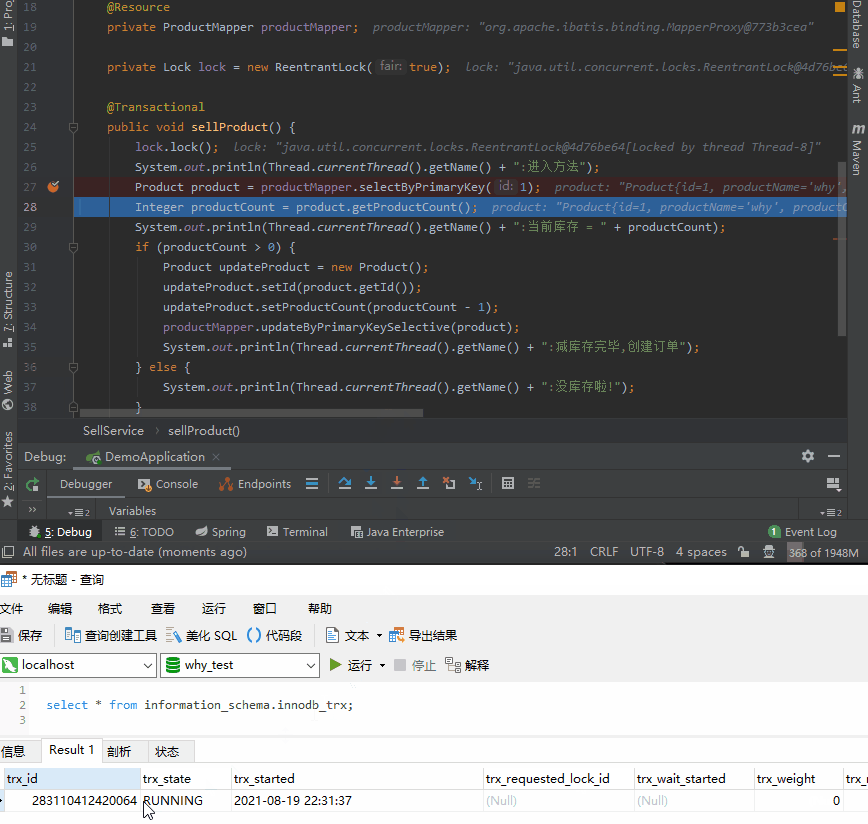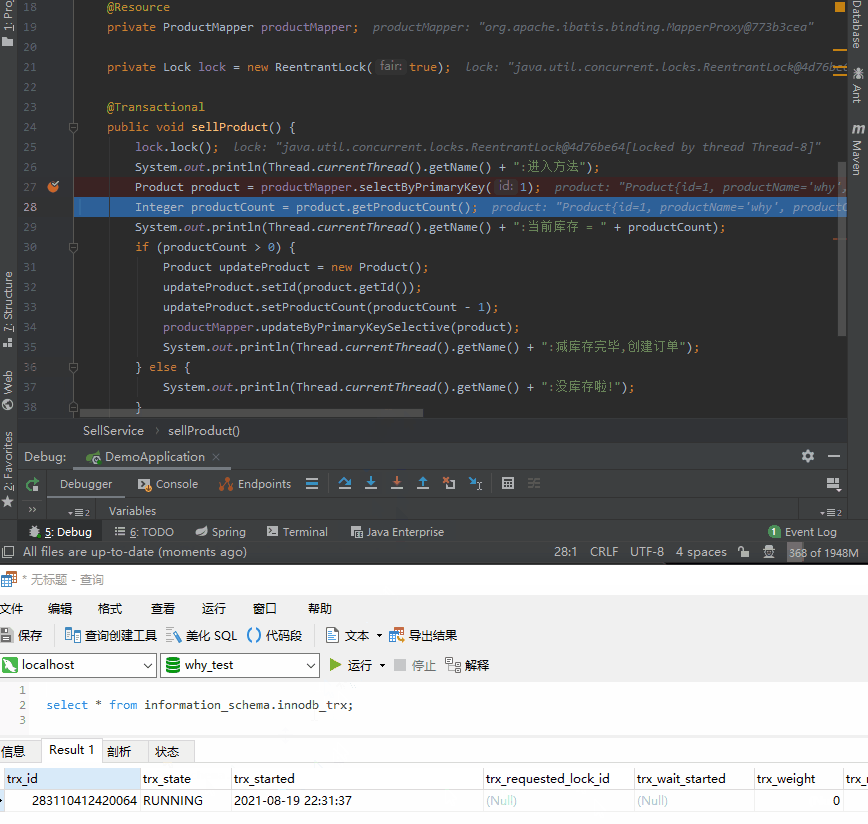
首先说一下这个 SQL:
select * from information_schema.innodb_trx;
不多解释,你只要知道这是查询当前数据库有哪些事务正在执行的语句就行。
你就注意看下面的动图,是不是第 27 行查询语句执行完成之后,查询事务的语句才能查出数据,说明事务这才真正的开启:
最后,我们把目光转移到这个方法的注释上:
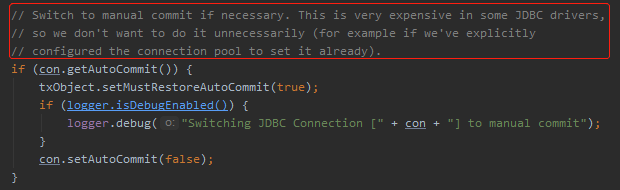
写这么长一段注释,意思就是给你说,这个参数我们默认是 ture,原因就是在某些 JDBC 的驱动中,切换为自动提交是一个很重的操作。
那么在哪设置的为 true 呢?
没看到代码,我一般是不死心的。
所以,一起去看一眼。
setAutoCommit 这个方法有好几个实现类,我也不知道具体会走哪一个:
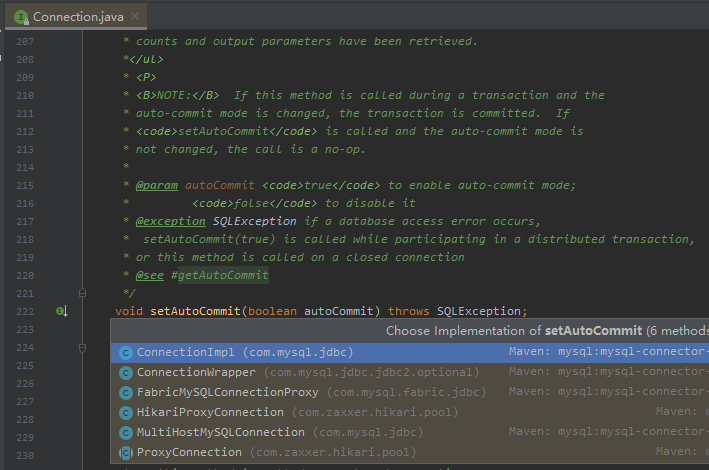
所以,我们可以在下面这个接口打上一个断点:
java.sql.Connection#setAutoCommit

然后重启程序,IDE 会自动帮你判断走那个实现类的:
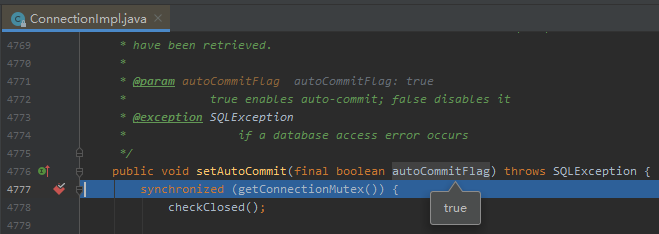
可以看到,默认确实是 true。
等等,你不会真的以为我是想让你看这个 true 吧?
我是想让你知道这个调试技巧啊。
不知道有多少个小伙伴曾经问过我:这个接口实现类好多啊,我怎么知道在哪打断点啊?
我说:很简单啊,就在每个实现类的第一行代码打上断点就好了。
然后他说:别闹,我经常给你的文章一键三联。
我当时就被感动了,既然是这样的好读者,我当然把可以直接在接口上打断点的这个小技巧教给他啦。

好了,不扯远了。
再说一个小细节,这一小节就收尾。
你再去看这小节的开头,我直接说答案藏在这个方法里面:
org.springframework.jdbc.datasource.DataSourceTransactionManager#doBegin
直接把答案告诉你了,隐去了探索的过程。
但是这个东西,就像是数学公式推导一样,省略了一步,就会让人看起来一脸懵逼。
就像下面这个小耗子一样:

所以,我是怎么知道在这个地方打断点的呢?
答案就是调用栈。
先给大家看一下我的代码:
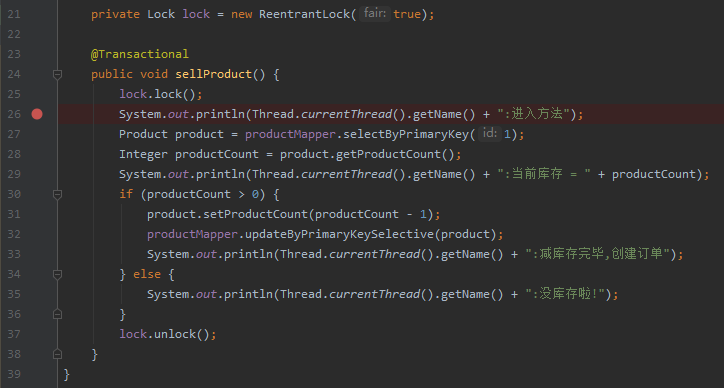
啥也先不管,上来就先在 26 行,方法入口处打上断点,跑起来:
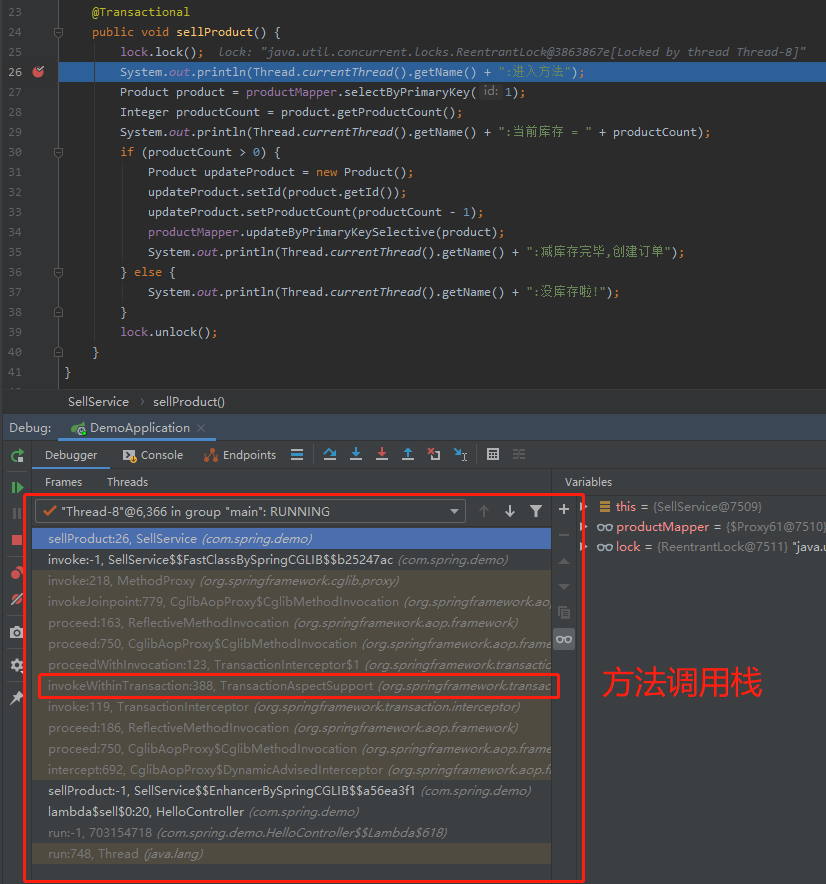
诶,你看这个调用栈,我框起来的这个地方:
看这个名字,你就不好奇吗?
它简直就是在跳着脚,在喊你:点我,快,愣着干啥,你TM快点我啊。我这里有秘密!
然后,我就这样轻轻的一点,就到了这里:
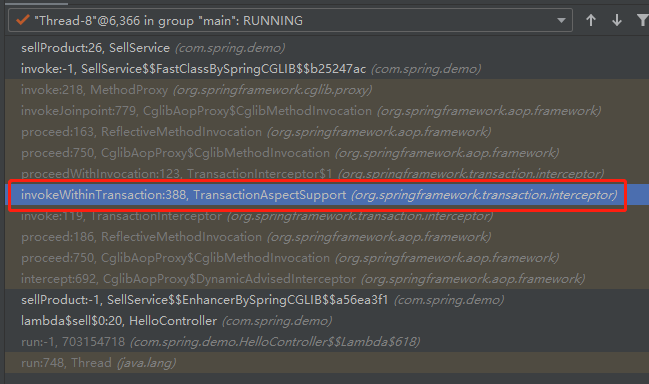
org.springframework.transaction.interceptor.TransactionAspectSupport#invokeWithinTransaction
这里有个切面,可以理解为 try 里面就是在执行我们的业务代码逻辑:
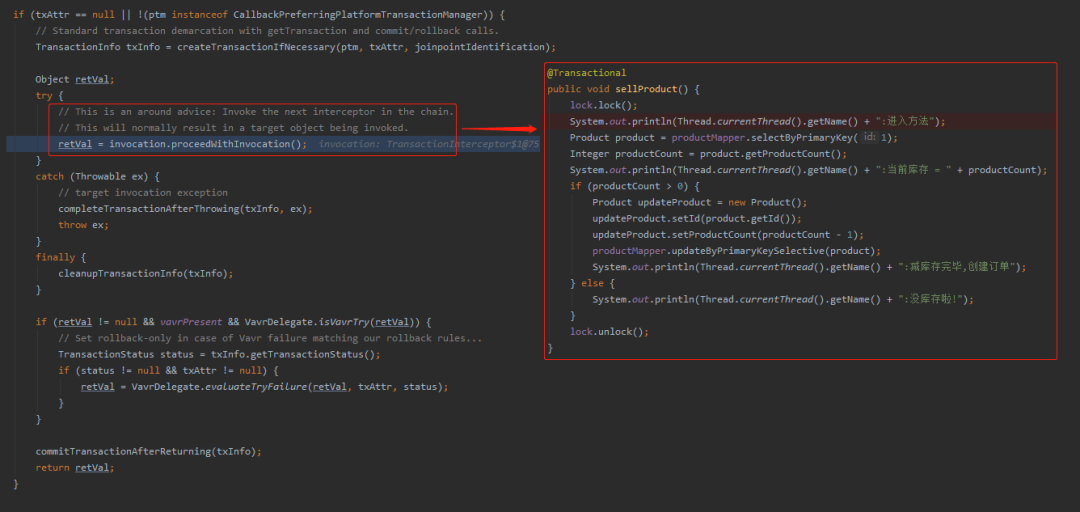
而在 try 代码块,执行我们的业务代码之前,有这样的一行代码:
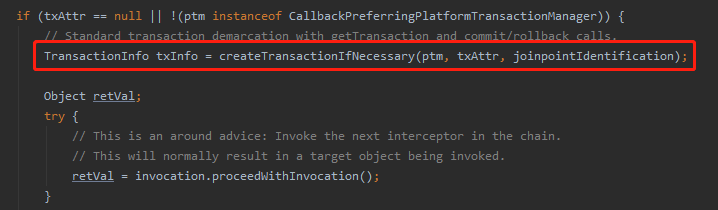
找到这里了,你就在这一行代码之前,再轻轻的打个断点,然后调试进去,就能找到这一小节开始的时候,说的这个方法:
org.springframework.jdbc.datasource.DataSourceTransactionManager#doBegin
不信?你看嘛,我不骗你。
它们之间只隔了三个调用:
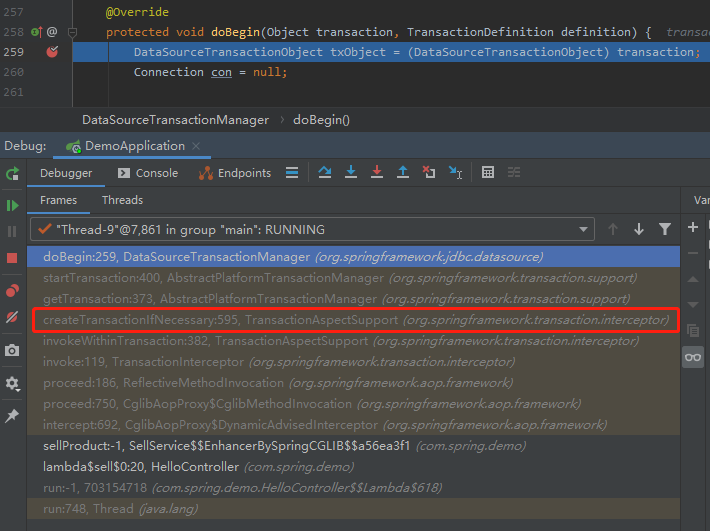
这样就找到答案了。
调用栈,另一个调试源码小技巧,屡试不爽,送给你。
之前还是之后
好了,前面是开胃菜,可能有的同学吃开胃菜就已经弄饱了。
没事,现在上正餐,再按一按还是能吃进去的。

还是拿前面的这份代码来说事,流程就是这样的:
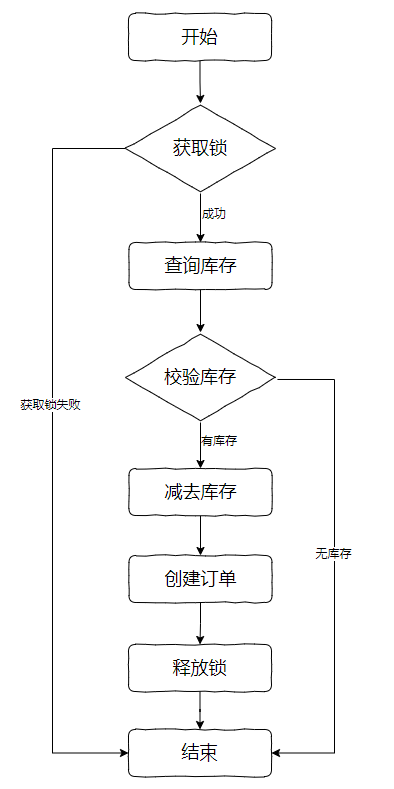
- 1.先拿锁。
- 2.查询库存。
- 3.判断是否还有库存。
- 4.有库存则执行减库存,创建订单的逻辑。
- 5.没有库存则返回。
- 6.释放锁。
所以代码是这样的:
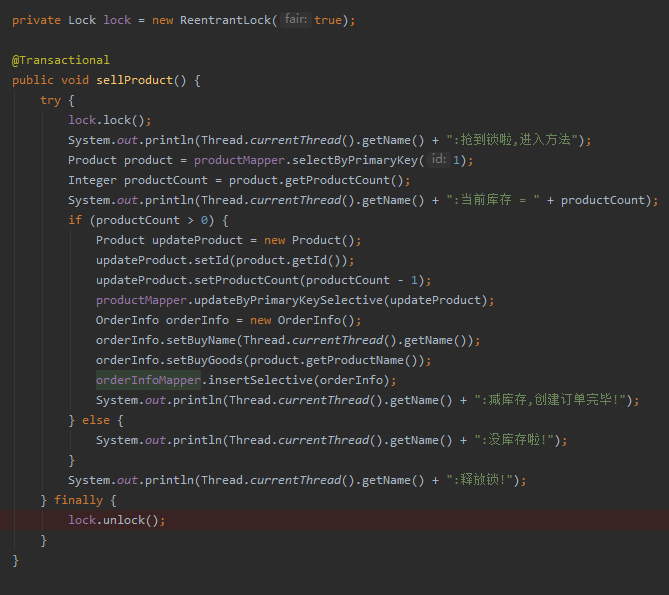
完全符合我们之前的那份代码片段,有事务,也有锁:
回到我们最开始抛出来的问题:
在上面的示例代码的情况下那么事务的提交到底是在 unlock 之前还是之后呢?
我们可以带入一个具体的场景。
比如我数据库里面有 10 个顶配版的 iPad,原价 1.6w 元一台,现在单价 1w 一个,这个价格够秒杀吧?
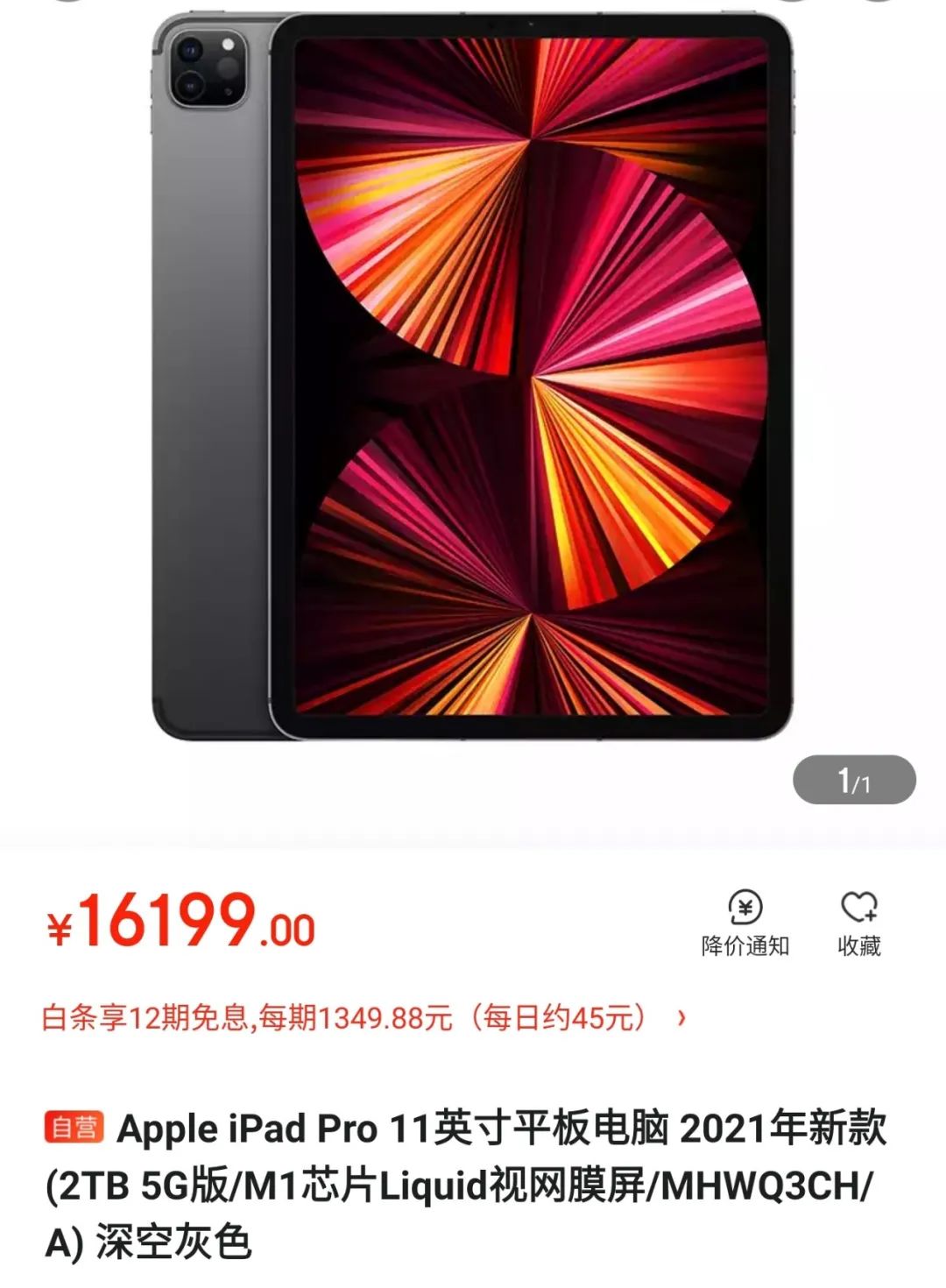
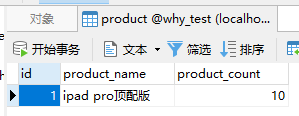
反正一共就 10 台,所以,我的数据库里面是这样的,
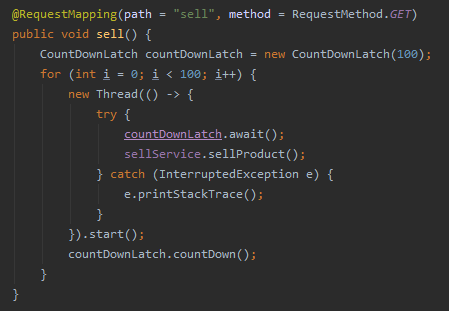
然后我搞 100 个人来抢东西,不过分吧?
我这里用 CountDownLatch 来模拟一下并发:
执行一下,先看结果,立马就见分晓:
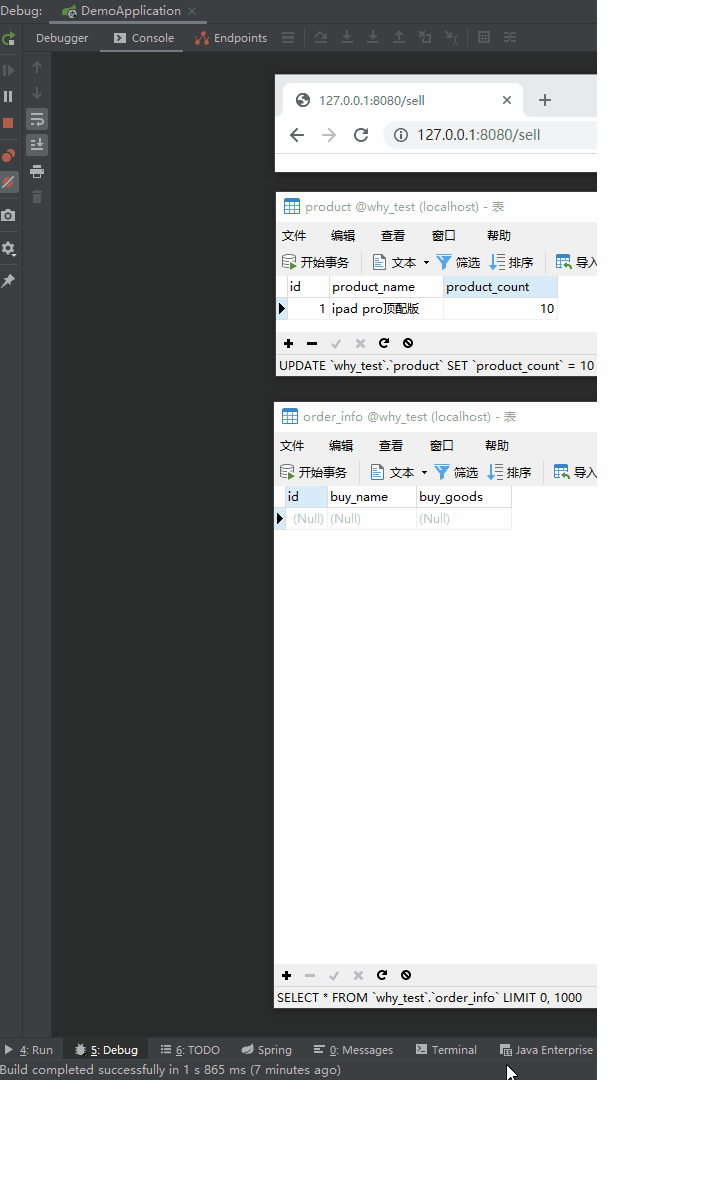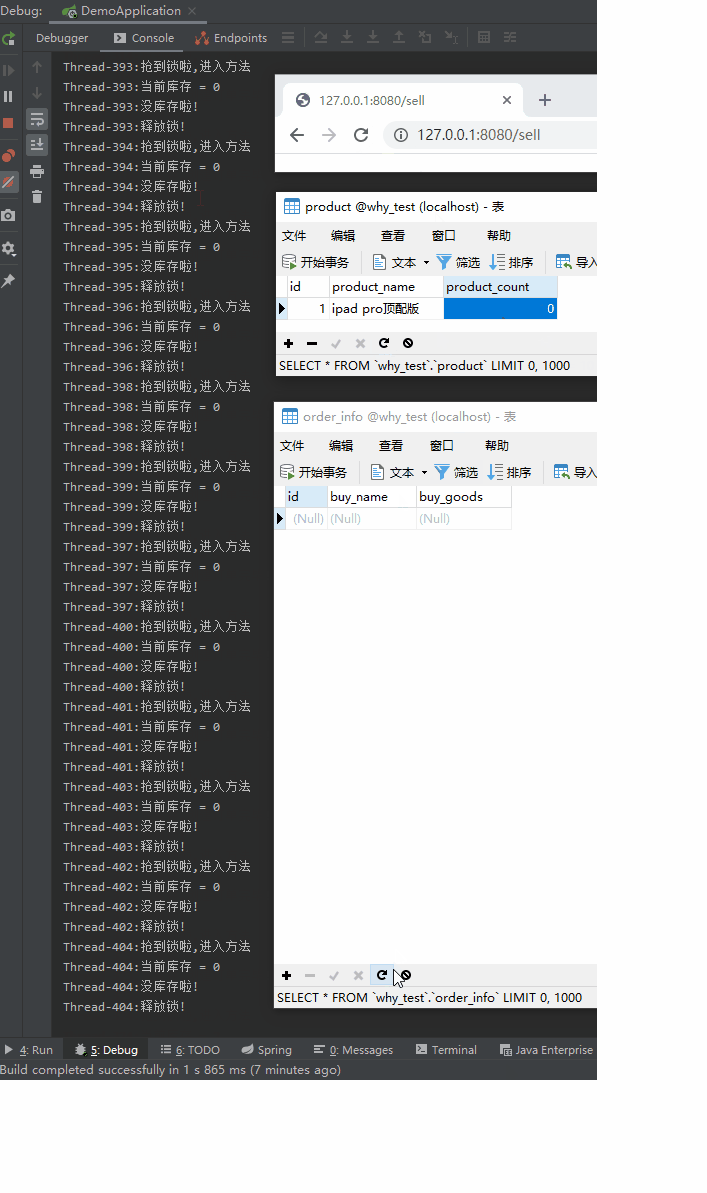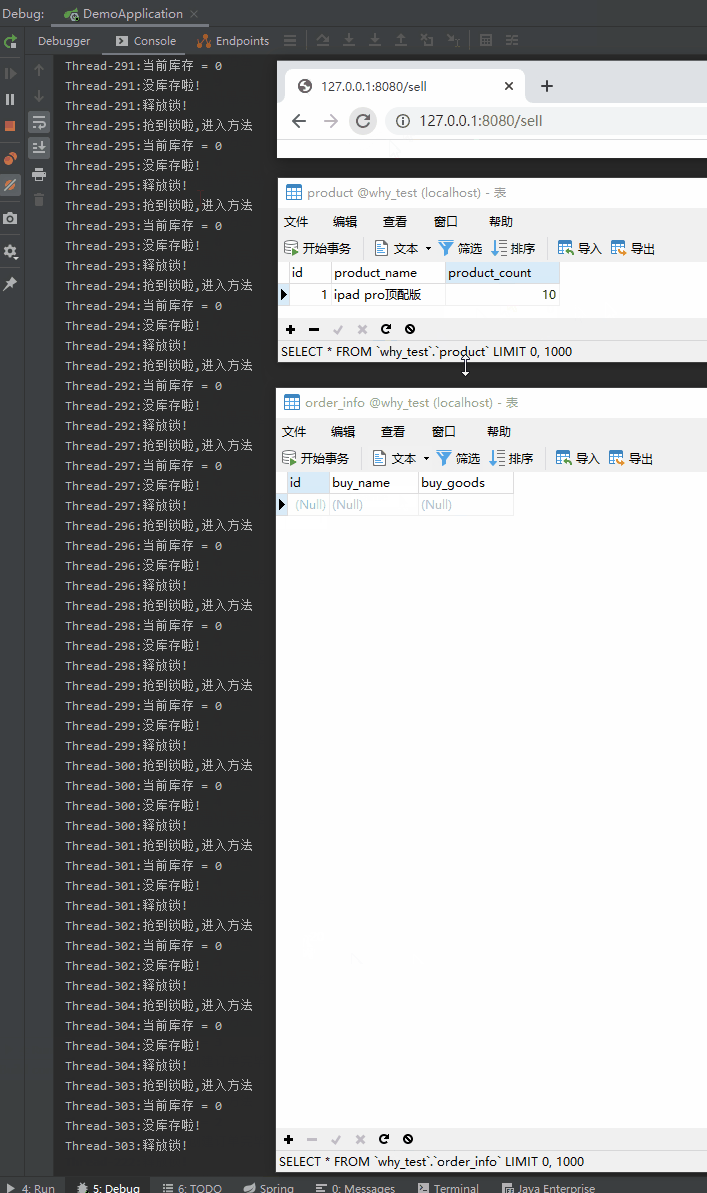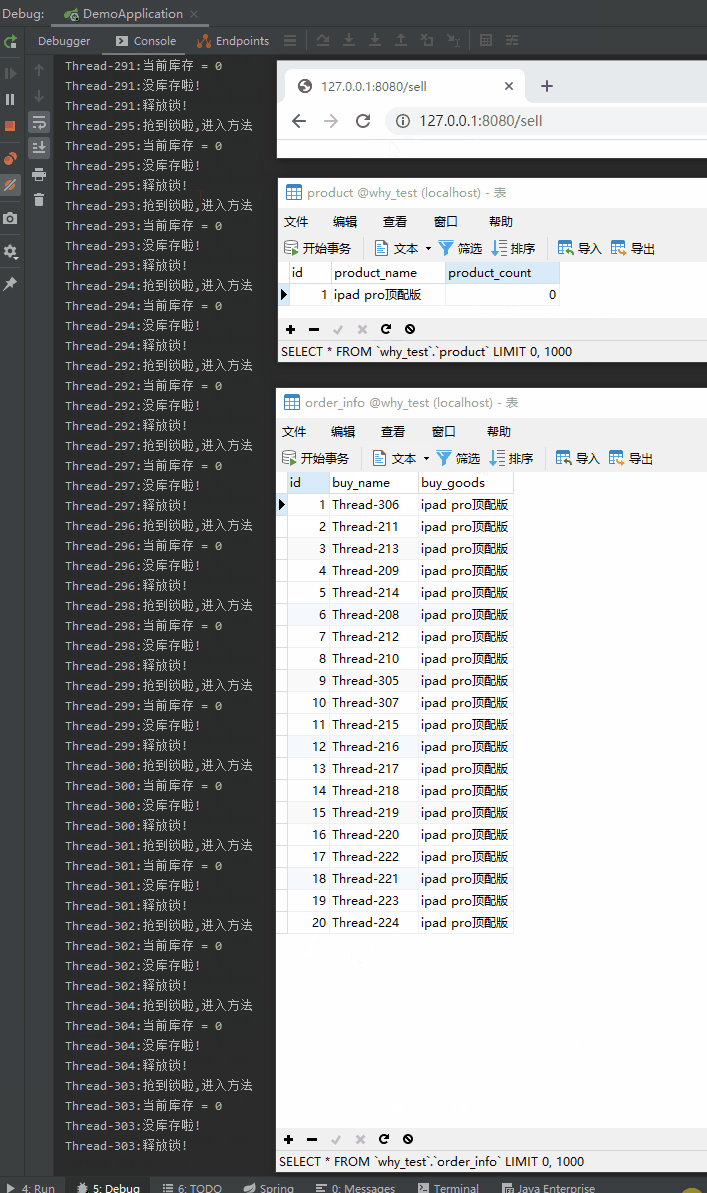
动图右边的部分:
上面是浏览器请求,触发 Controller 的代码。
然后中间是产品表,有 10 个库存。
最下面是订单表,没有一条数据。
触发了代码之后,库存为 0 了,没有问题。
但是,订单居然有 20 笔!
也就是说超卖了 10 个ipad pro 顶配版!
超卖的,可不在活动预算范围内啊!
那可就是一个 1.6w 啊,10 个就是 16w 啊。
就这么其貌不扬,人畜无害,甚至看起来猥猥琐琐的代码,居然让我亏了整整 16w 。

其实,结果出现了,答案也就随之而来了。
在上面的示例代码的情况下,事务的提交在 unlock 之后。
其实你仔细分析后,猜也能猜出来,肯定是在 unlock 之后的。
而且上面的描述“unlock之后”其实是有一定的迷惑性的,因为释放锁是一个比较特别的操作。
换一个描述,就比较好理解了:
在上面的示例代码的情况下,事务的提交在方法运行结束之后。
你细品,这个描述是不是迷惑性就没有那么强了,甚至你还会恍然大悟:这不是常识吗?

为什么是方法结束之后,分析具体原因之前,我想先简单分析一下这样的代码写出来的原因。
我猜可能是这样的。
最开始的代码结构是这样:

然后,写着写着发现不对,并发的场景下,库存是一个共享的资源,这玩意得加锁啊。
于是搞了这出:

后面再次审查代码的时候,发现:哟,这个第三步得是一个事务操作才行呀。
于是代码就成了这样:

演进路线非常合理,最终的代码看起来也简直毫无破绽。
但是问题到底出在哪里了呢?

找答案
答案还是在这个类里面:
org.springframework.transaction.interceptor.TransactionAspectSupport#invokeWithinTransaction
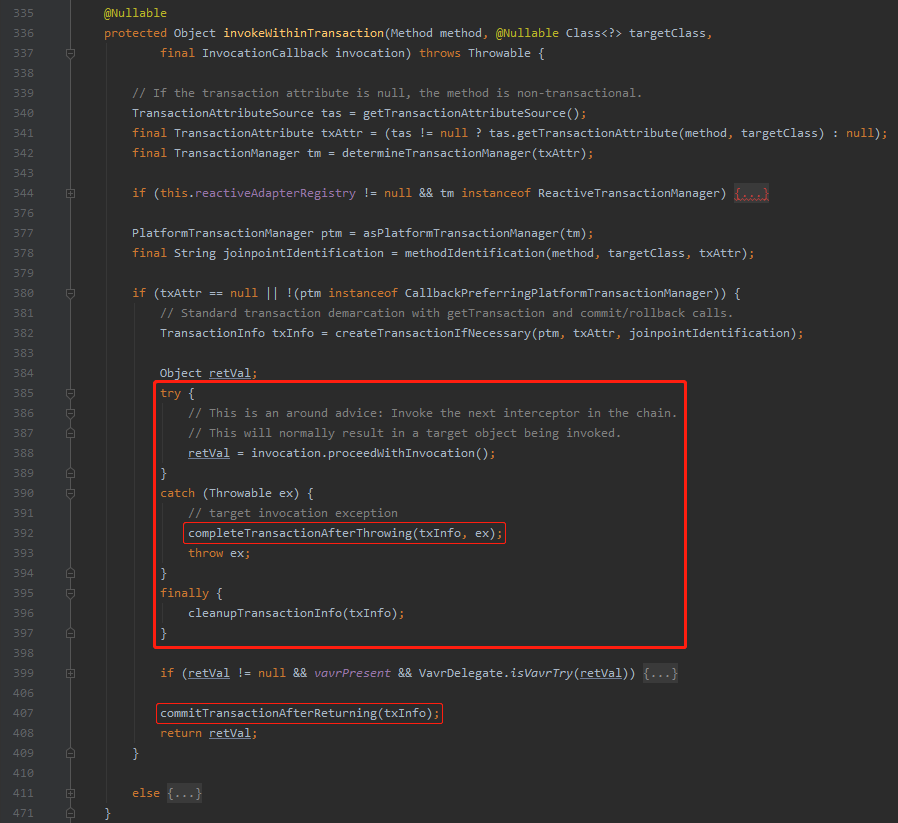
前面我们聊事务开启的时候,说的是第 382 行代码。
然后 try 代码块里面执行的是我们的业务代码。
现在,我们要研究事务的提交了,所以主要看我框起来的地方。
首先 catch 代码块里面,392 行,看方法名称已经非常的见名知意了:
completeTransactionAfterThrowing 在抛出异常之后完成事务的提交。
你看我的代码,只是用到了 @Transactional 注解,并没有指定异常。
那么问题就来了:
Spring 管理的事务,默认回滚的异常是什么呢?
如果你不知道答案,就可以带着问题去看源码。
如果你知道答案,但是没有亲眼看到对应的代码,那么也可以去寻找源码。
如果你知道答案,也看过这部分源码,温故而知新。
先说答案:默认回滚的异常是 RuntimeException 或者 Error。
我只需要在业务代码里面抛出一个 RuntimeException 的子类,比如这样的:
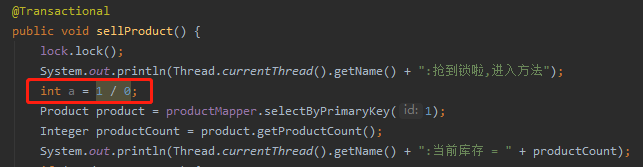
然后在 392 行打上断点,开始调试就完事了:
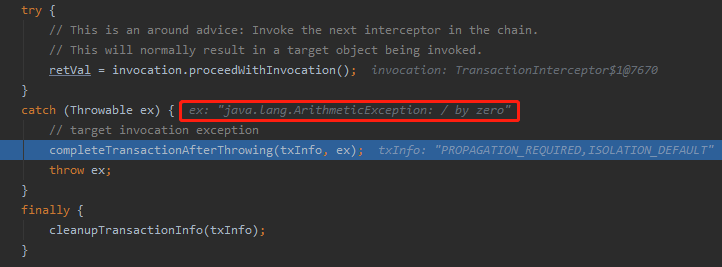
只需要往下调试几步,你就能走到这个方法来:
org.springframework.transaction.interceptor.RuleBasedTransactionAttribute#rollbackOn
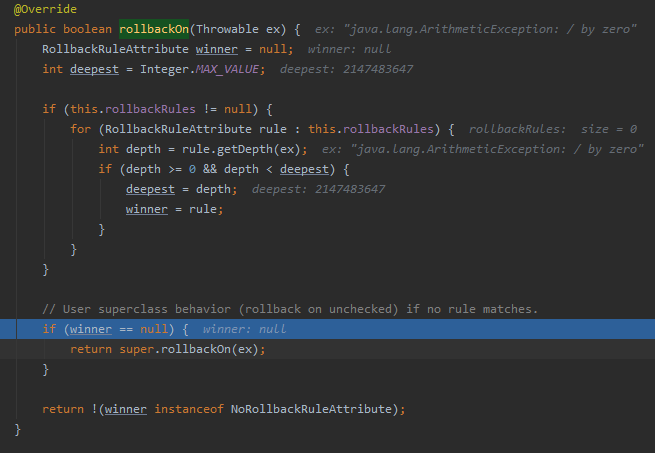
发现这个 winner 对象为空,接着走了这个逻辑:
return super.rollbackOn(ex);
答案就藏着这行代码的背后:

如果异常类型是 RuntimeException 或者 Error 的子类,那么就返回 true,即需要回滚,调用 rollback 方法:
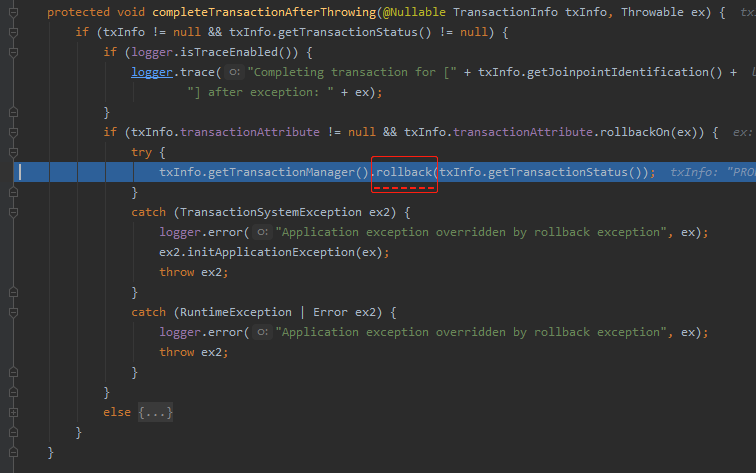
如果返回为 false,则表示不需要回滚,调用 commit 方法:
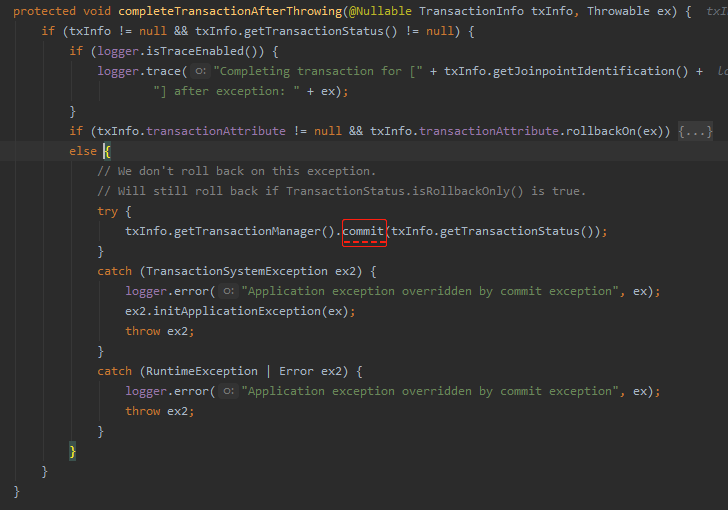
那么怎么让它返回 false 呢?
很简单嘛,这样一搞就好了:
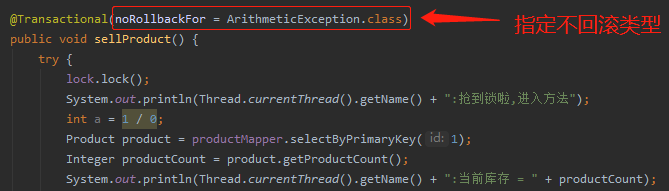
框架给你留了口子,你就把它用起来。
当我把代码改成上面那样,然后重新启动项目,再次访问代码。
我们去寻找出现指定异常不回滚的具体的实现逻辑在哪。
其实也在我们刚刚看到的方法里面:
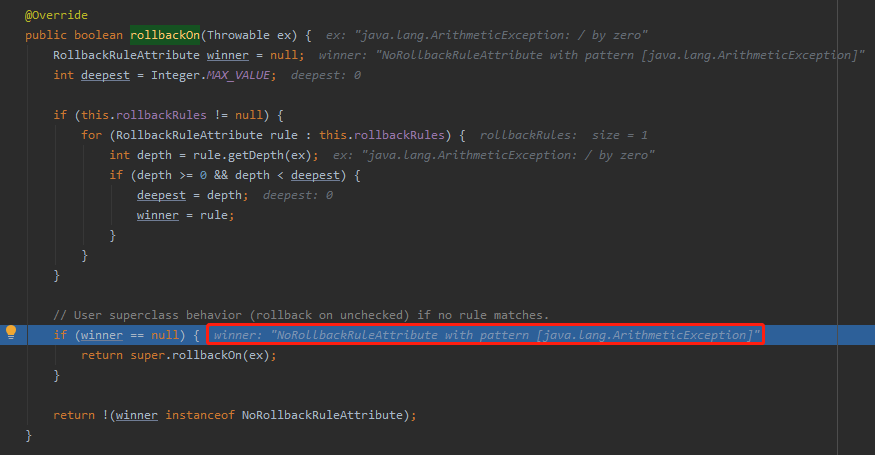
你看,这个时候 winner 不为 null 了。它是一个 NoRollbackRuleAttribute 对象了。
所以就走入这行代码,返回 false 了:
return !(winner instanceof NoRollbackRuleAttribute);
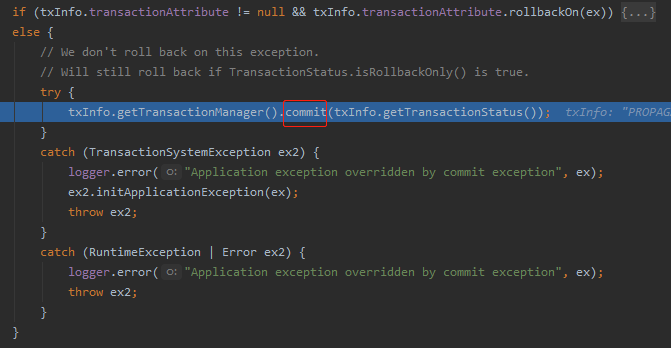
于是,就成功走到了 else 分支里面,出了异常也 commit 了,你说神奇不神奇:
写到这里的时候,我突然想到了一个骚操作,甚至有可能变成一道沙雕面试题:
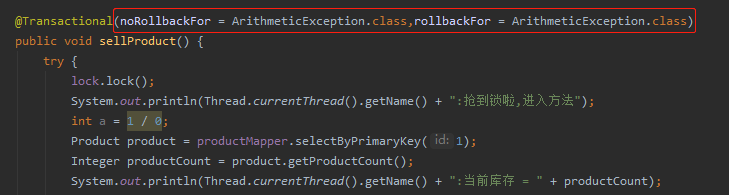
这个操作骚不骚,到底会回滚呢还是不回滚呢?

如果你在项目里看到这样的代码肯定是要骂一句傻逼的。
但是面试官就喜欢搞这些阴间的题目。
我想到这个问题的时候,我也不知道答案是什么,但是我知道答案还是在源码里面:
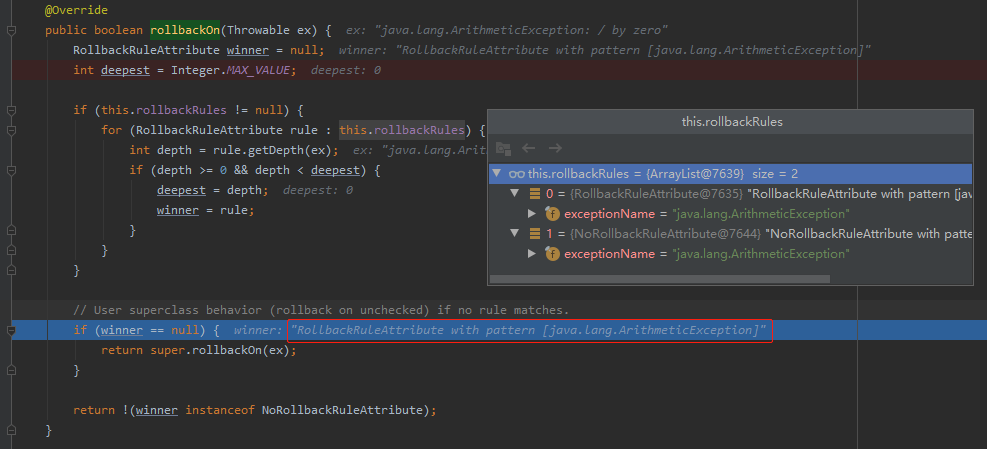
首先,从结果上可以直观的看到,经过 for 循环之后, winner 是 RollbackRuleAttribute 对象,所以下面的代码返回 true,需要回滚:
return !(winner instanceof NoRollbackRuleAttribute);
问题就变成了 winner 为什么经过 for 循环之后是 RollbackRuleAttribute?
答案需要你自己去调试一下,很容易就明白了,我描述起来比较费劲。
简单一句话:导致 winner 是 RollbackRuleAttribute 的原因,就是因为被循环的这个 list 是先把 RollbackRuleAttribute 对象 add 了进去。
那么为什么 RollbackRuleAttribute 对象先加入到集合呢?
org.springframework.transaction.annotation.SpringTransactionAnnotationParser#parseTransactionAnnotation(org.springframework.core.annotation.AnnotationAttributes)
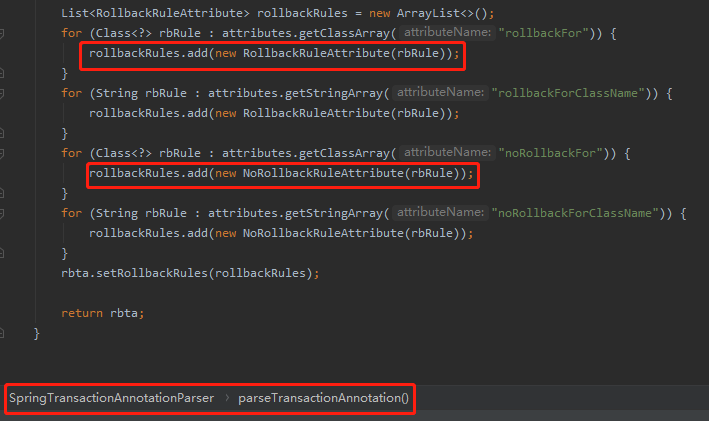
别问,问就是因为代码是这样写的。
为什么代码要这样写呢?
我想可能设计这块代码的开发人员觉得 rollbackFor 的优先级比 noRollbackFor 高吧。
再来一个问题:
Spring 源码怎么匹配当前这个异常是需要回滚的?
别想那么复杂,大道至简,直接递归,然后一层层的找父类,对比名称就完事了。
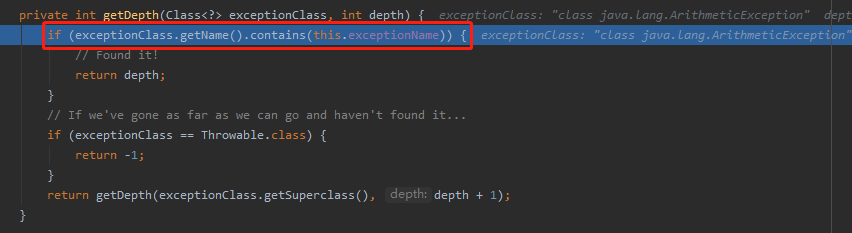
你注意截图里面的注释:
一个是 Found it!
表示找到了,匹配上了,用了感叹号表示很开心。
一个是 If we’ve gone as far as we can go and haven’t found it…
啥意思呢,这个 as far as 在英语里面是一个连词,表示“直到…为止…”的意思。引导的是状语从句,强调的是程度或范围。
所以,上面这句话的意思就是:
如果我们已经走到我们能走的最远的地方,还没匹配上,代码就只能这样写了:

异常类,最远的地方就是 Throwable.class。没匹配上,就返回 -1。
好了,通过两个没啥卵用的知识点,顺带学了点实战英语,关于业务代码出了异常回滚还是提交这一块的代码就差不多了。
但是我还是建议大家亲自去 Debug 一下,可太有意思了。
然后我们接着聊正常场景下的提交。
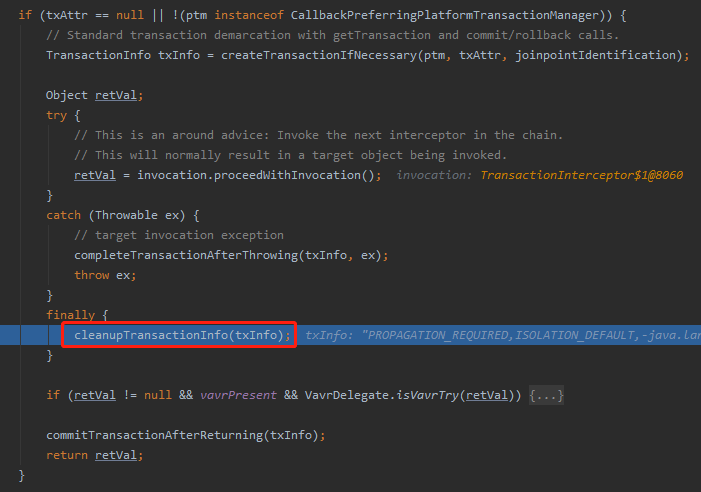
这个代码块里面,try 我们也聊了,catch 我们也聊了。
就差个 finally 了。
我看网上有的文章说 finally 里面就是 commit 的地方。
错了啊,老弟。
这里只是把数据库连接给重置一下。
方法上已经给你说的很清楚了:
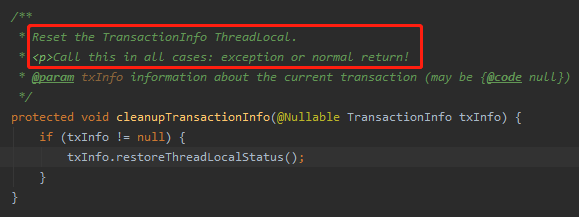
Spring 的事务是基于 ThreadLocal 来做的。在当前的这个事务里面,可能有一些隔离级别、回滚类型、超时时间等等的个性化配置。
不管是这个事务正常返回还是出现异常,只要它完事了,就得给把这些个性化的配置全部恢复到默认配置。
所以,放到了 finally 代码块里面去执行了。
真正的 commit 的地方是这行代码:
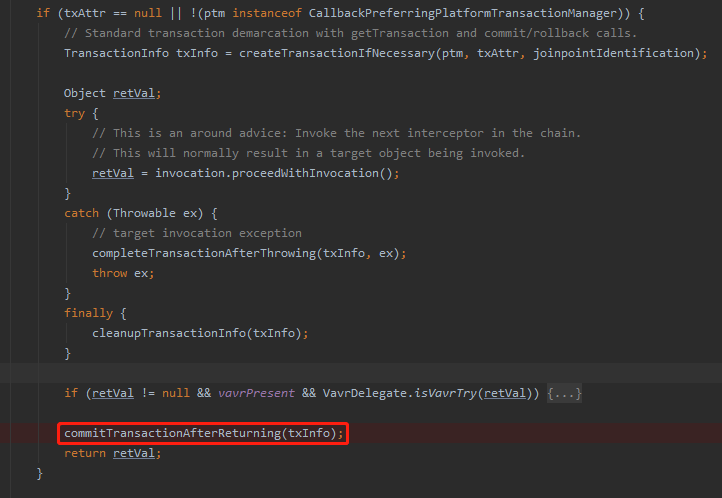
那么问题又来了:
走到这里来了,事务一定会提交吗?
话可别说的那么绝对,兄弟,看代码:
org.springframework.transaction.support.AbstractPlatformTransactionManager#commit
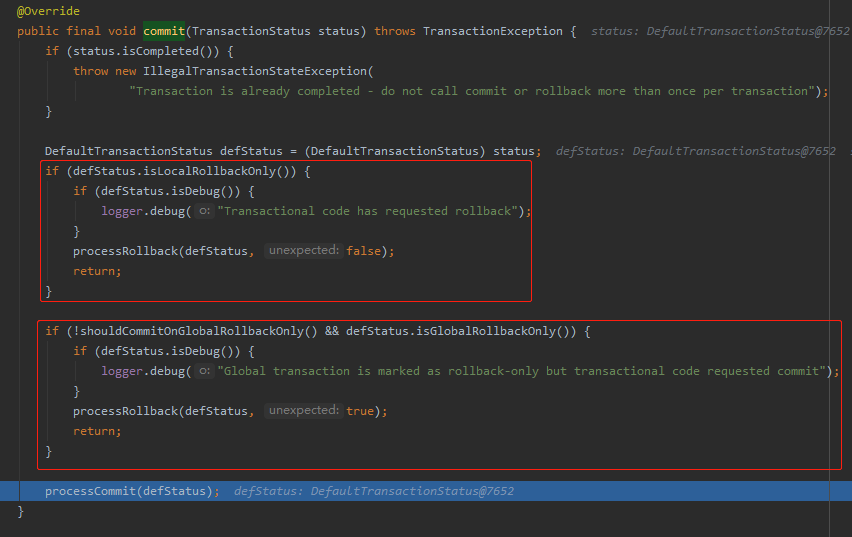
在 commit 之前还有两个判断,如果事务被标记为 rollback-only 了,还是得回滚。
而且,你看日志。
我这事务还没提交呢,锁就被释放了?
接着往下看 commit 相关的逻辑,我们就会遇到老朋友:
HikariCP,SpringBoot 2.0 之后的默认连接池,强得一比,在之前的文章里面介绍过。
关于事务的提交,就不大篇幅的介绍了。
给大家指个路:
com.mysql.cj.protocol.a.NativeProtocol#sendQueryString
在这个方法的入口处打上断点:

然后你会发现很多的 SQL 都会经过这个地方。
所以,为了你顺利调试,你需要在断点上设置一下:
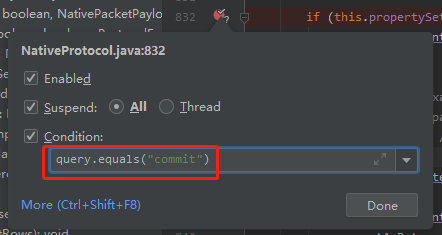
这样只有 SQL 语句是 commit 的时候才会停下来。
又一个调试小细节,送给你,不客气。
现在,我们知道原因了,那我现在把代码稍微变一下:
把 ReentrantLock 换成了 synchronized。
那你说这个代码还会不会有问题?

说没有问题的同学请好好反思一下。
这个地方的原理和前面讲的东西是一模一样的呀,肯定也是有问题的。
这个加锁方式就是错误的。
所以你记住了,以后面试官问你 @Transactional 的时候,你把标准答案先背一遍之后,如果你对锁这块的知识点非常的熟悉,就可以在不经意间说一下结合锁用的时候的异常场景。
别说你写的,就说你 review 代码的时候发现的,深藏功与名。
另外记得扩展一下,现在都是集群服务了,加锁得上分布式锁。
但是原理还这个原理。
既然都聊到分布式锁了,这和面试官又得大战几个回合。
是你主动提起的,把面试官引到了你的主战场,拿几分,不过分吧。
一个面试小技巧,送给你,不客气。
解决方案
现在我们知道问题的原因了。
解决方案其实都呼之欲出了嘛。
正确的使用锁,把整个事务放在锁的工作范围之内:

这样,就可以保证事务的提交一定是在 unlock 之前了。
对不对?

说对的同学,今天就先到这里,请回去等通知啊。
别被带到沟里去了呀,朋友。
你仔细想想这个事务会生效吗?
提示到这里还没想明白的同学,赶紧去搜一下事务失效的几种场景。
我这里说一个能正常使用的场景:
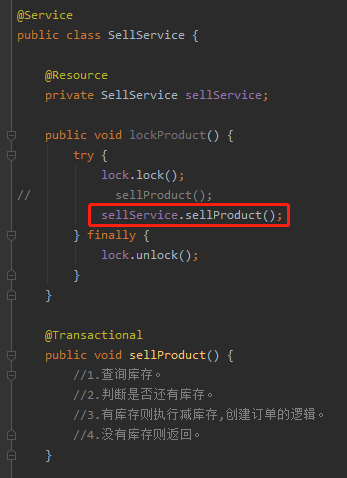
只是这种自己注入自己的方式,我觉得很恶心。
如果项目里面出现了这样的代码,一定是代码分层没有做好,项目结构极其混乱。
不推荐。
还可以使用编程式事务的方式去写,自己去控制事务的开启、提交、回滚。
比直接使用 @Transactional 靠谱。
除此之外,还有一个骚一点的解决方案。
其他地方都不动,就只改一下 @Transactional 这个地方:
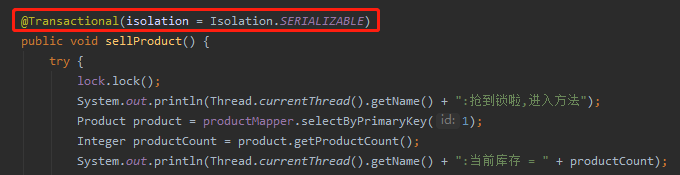
把隔离级别串行化,再次跑测试用例,绝对不会出现超卖的情况。
甚至都不需要加锁的逻辑。
你觉得好吗?

好啥啊?
串行化性能跟不上啊!
这玩意太悲观了,对于同一行的数据,读和写的时候都会进行加锁操作。当读写锁出现冲突的时候,后面来的事务就排队等着。
这个骚操作,知道就行了,别用。
你就当是一个没啥卵用的知识点就行了。
但是,如果你们是一个不追求性能的场景,这个没有卵用的知识点就变成骚操作了。
rollback-only
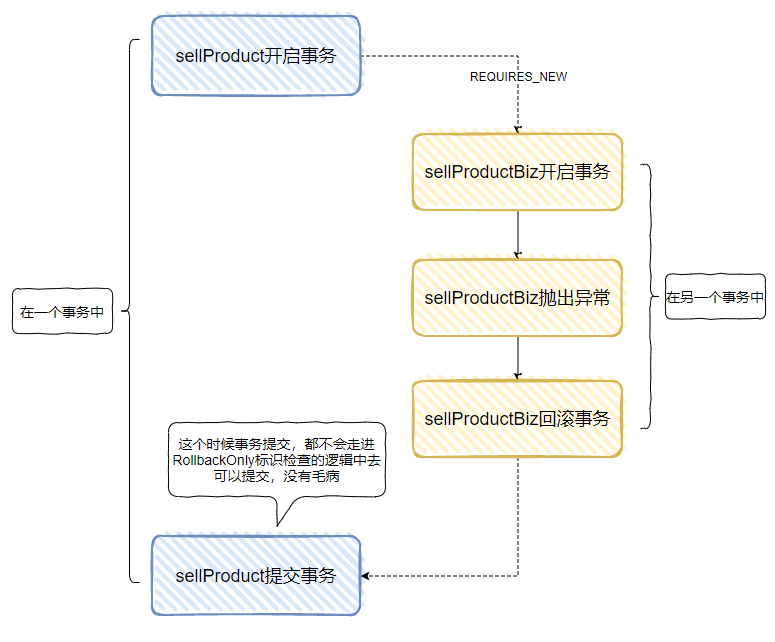
前面提到了这个 rollback-only,为了更好的行文,所以我一句话就带过了,其实它也是很有故事的,单独拿一节出来简单说一下,给大家模拟一下这个场景。
以后你见到这个异常就会感觉很亲切。
Spring 的事务传播级别默认是 REQUIRED,含义是如果当前没有事务,就新建一个事务,如果上下文中已经有一个事务,则共享这个事务。
直接上代码:
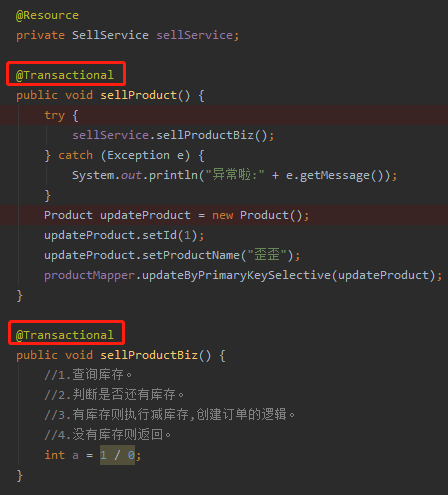
这里有 sellProduct、sellProductBiz 两个事务,sellProductBiz 是内层事务,它会抛出了异常。
当执行整个逻辑的时候,会抛出这个异常:
Transaction rolled back because it has been marked as rollback-only
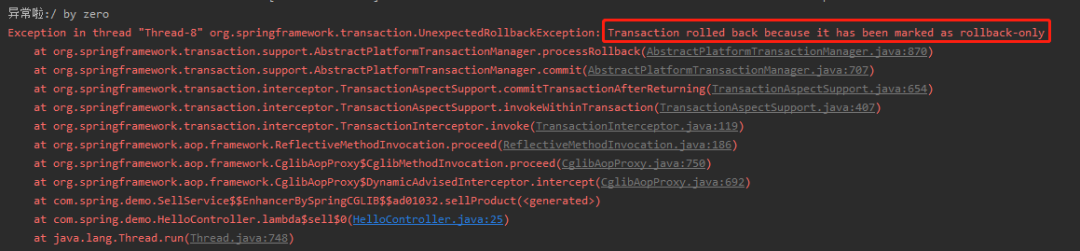
根据这个异常的堆栈,可以找到这个地方,在前面出现过:
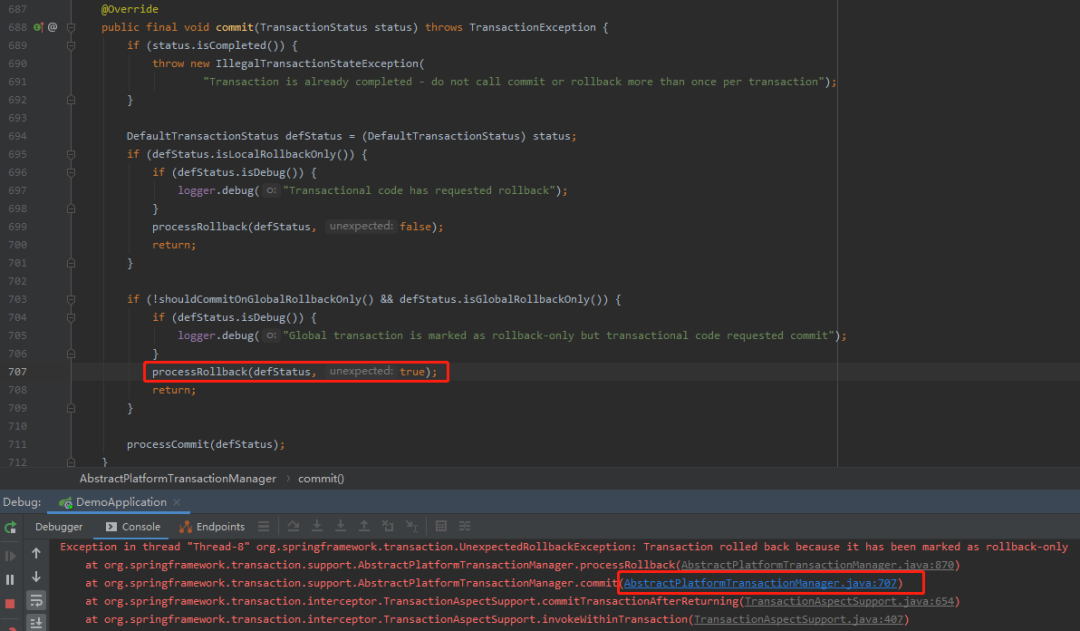
所以,我们只需要分析这个 if 条件为什么满足了,就大概摸清楚脉络了。
if (!shouldCommitOnGlobalRollbackOnly() && defStatus.isGlobalRollbackOnly())
前面的 shouldCommitOnGlobalRollbackOnly 默认为 false:

问题就精简为了:defStatus.isGlobalRollbackOnly() 为什么是true?
为什么?
因为 sellProductBiz 抛出异常后,会调用 completeTransactionAfterThrowing 方法执行回滚逻辑。
肯定是这个方法里面搞事情了啊。
org.springframework.transaction.support.AbstractPlatformTransactionManager#processRollback
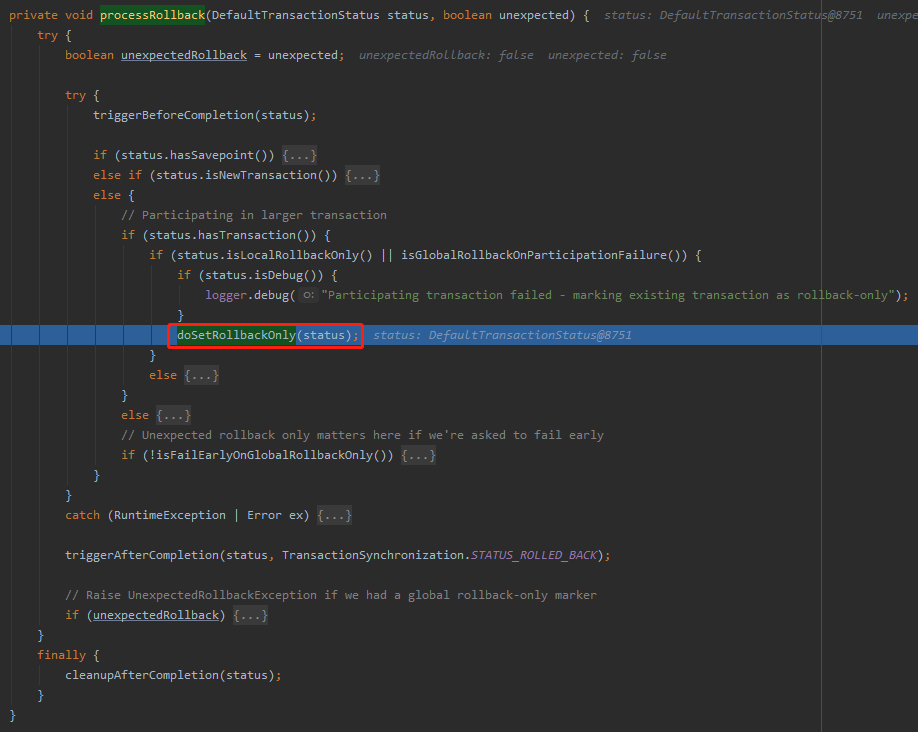
在这里,把链接的 rollbackOnly 置为了 true。
所以,后面的事务想要 commit 的时候,一检查这个参数,哦豁,回滚吧。
大概就是这样的:
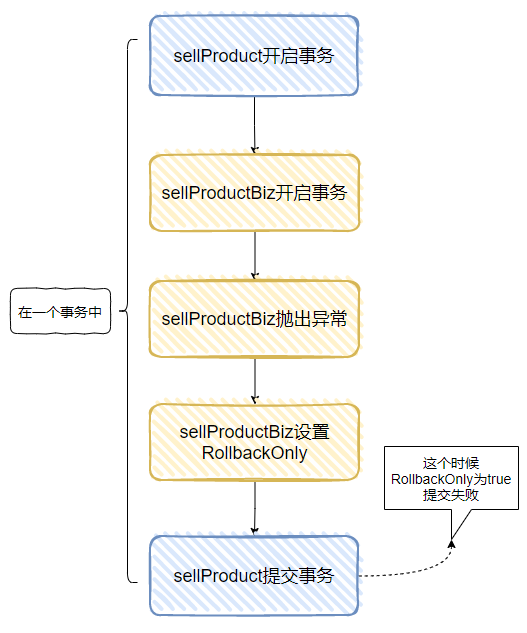
如果这不是你期望的异常,怎么解决呢?
理解了事务的传播机制就简单的一比:
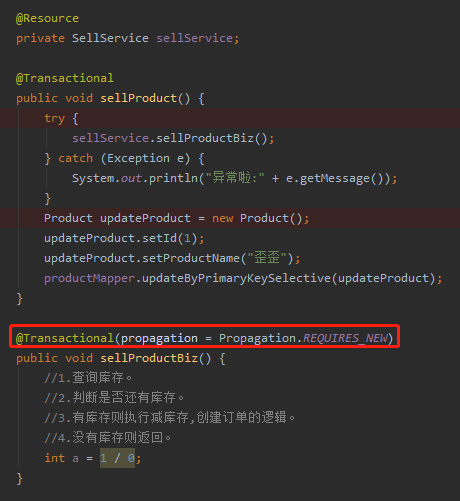
就这样,跑起来没毛病,互不干扰。

评论区