


前言
本文稍微有点点长,但总结了jdk8的新特性 以后面试官要是问起JDK8有哪些新特性,你就不怕答不上来了!
该篇为个人的笔记,如有不足,欢迎补充…
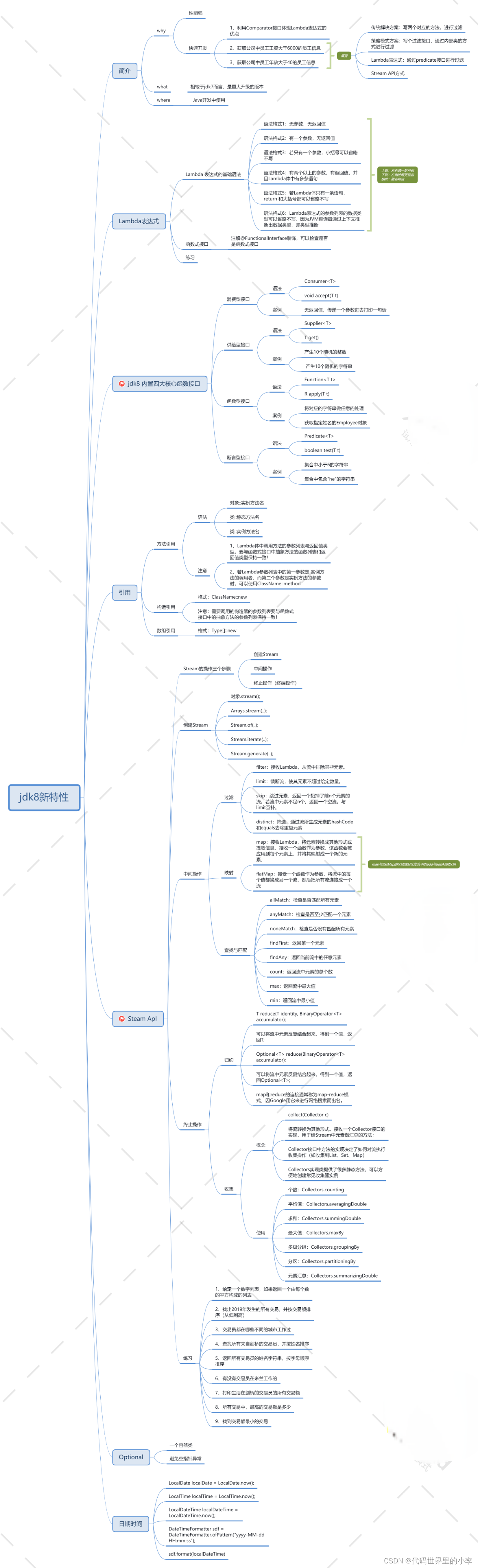
一、jdk8简介
Oracle甲骨文公司于2015年1月15日发布了新一版JDK8,新版本加入了许多新的特性。这些特性带来了一些改变,可以很大方便Java程序的编写。新特性主要涉及:对于JDK7中Fork/Join并行处理的升级;支持Lambda表达式;添加了Stream API;对于注解的拓展,加入了类型注解、重复注解;在G1回收器中支持字符串去重;内存空间中删除了永久代,引入了元空间。
**细节:**性能强 快速开发
怎么做到了快速开发?
1、利用Comparator接口体现Lambda表达式的优点
2、获取公司中员工工资大于6000的员工信息
3、获取公司中员工年龄大于40的员工信息
概要
传统解决方案:写两个对应的方法,进行过滤
策略模式方案:写个过滤接口,通过内部类的方式进行过滤
Lambda表达式:通过predicate接口进行过滤
Stream API方式
实体类Employee
package com.javaxl.lambda; /** * @author 代码世界里的小李 * @site www.javaxl.com * @company javaxl * @create 2022-01-08 12:24 */ public class Employee { private String name; private int age; private float salary; @Override public String toString() { return "Employee{" + "name='" + name + '\'' + ", age=" + age + ", salary=" + salary + '}'; } public Employee() { } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public float getSalary() { return salary; } public void setSalary(float salary) { this.salary = salary; } public Employee(String name, int age, float salary) { this.name = name; this.age = age; this.salary = salary; } }简单了解Lambda表达式的优点
package com.javaxl.lambda; import org.junit.Before; import org.junit.Test; import java.util.*; import java.util.function.Predicate; /** * @author 代码世界里的小李 * @site www.javaxl.com * @company javaxl * @create 2022-01-08 12:34 */ public class Demo1 { List<Employee> employees; @Before public void before(){ employees = Arrays.asList(new Employee("zhangsan",22,8888.8f), new Employee("lisi",44,6666.6f), new Employee("wangwu",55,4444.4f), new Employee("maliu",11,1111.1f), new Employee("tianqi",77,7777.7f), new Employee("wangba",33 ,3333.3f), new Employee("zhaojiu",99,5656.7f), new Employee("huoying",56,8787.6f)); } // 匿名函数调用(jdk8出现之前) @Test public void test1(){ Comparator<Integer> comparator = new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { // return -(o1-o2); return -Integer.compare(o1,o2); } }; Set set = new TreeSet(comparator); set.add(3); set.add(9); set.add(7); set.add(6); set.add(2); set.add(5); System.out.println(set); } // lambda表达式写法(jdk8出现之后) @Test public void test2(){ Comparator<Integer> comparator = (x,y)->-Integer.compare(x,y); Set set = new TreeSet(comparator); set.add(3); set.add(9); set.add(7); set.add(6); set.add(2); set.add(5); System.out.println(set); } // 需求:获取公司中员工工资大于6000的员工信息 private List<Employee> filter1(List<Employee> list){ List<Employee> list1 = new ArrayList<>(); for (Employee employee : list) { if (employee.getSalary() > 6000){ list1.add(employee); } } return list1; } // 需求:获取公司中员工年龄大于40的员工信息 private List<Employee> filter2(List<Employee> list){ List<Employee> list1 = new ArrayList<>(); for (Employee employee : list) { if (employee.getAge() > 40){ list1.add(employee); } } return list1; } // 具有一定共性,变化的需求 // 传统方案 @Test public void test3(){ for (Employee employee : this.filter1(employees)) { System.out.println(employee); } System.out.println("========================================="); for (Employee employee : this.filter2(employees)) { System.out.println(employee); } } // 需求:获取公司中员工工资大于6000的员工信息 // 需求:获取公司中员工年龄大于40的员工信息 private List<Employee> filter3(List<Employee> list,MyPredicate<Employee> mp){ List<Employee> list1 = new ArrayList<>(); for (Employee employee : list) { if (mp.test(employee)){ list1.add(employee); } } return list1; } // 优化:利用策略模式+Lambda表达式 @Test public void test4(){ for (Employee employee : this.filter3(employees,(mp)->mp.getSalary()>6000)) { System.out.println(employee); } System.out.println("========================================="); for (Employee employee : this.filter3(employees,(mp)->mp.getAge()>40)) { System.out.println(employee); } } // 需求:获取公司中员工工资大于6000的员工信息 // 需求:获取公司中员工年龄大于40的员工信息 private List<Employee> filter4(List<Employee> list, Predicate<Employee> mp){ List<Employee> list1 = new ArrayList<>(); for (Employee employee : list) { if (mp.test(employee)){ list1.add(employee); } } return list1; } // jdk8自带的predicate函数式接口 @Test public void test5(){ for (Employee employee : this.filter4(employees,(mp)->mp.getSalary()>6000)) { System.out.println(employee); } System.out.println("========================================="); for (Employee employee : this.filter4(employees,(mp)->mp.getAge()>40)) { System.out.println(employee); } } // Stream API @Test public void test6(){ employees.stream().filter((e)->e.getSalary()>6000).forEach(System.out::println); System.out.println("========================================="); employees.stream().filter((e)->e.getAge()>40).limit(3).forEach(System.out::println); } }
二、Lambda表达式语法
Java8中引入了一个新的操作符“->”,该操作符称为箭头操作符或Lambda操作符,箭头操作符将Lambda表达式拆成两部分:
左侧:Lambda表达式的参数列表
右侧:Lambda表达式中所需执行的功能,即Lambda体
- 使用Lambda必须有接口,并且接口中有且仅有一个抽象方法。
只有当接口中的抽象方法存在且唯一时,才可以使用Lambda,但排除接口默认方法以及声明中覆盖Object的公开方法。- 使用Lambda必须具有上下文推断。
也就是方法的参数或局部变量类型必须为Lambda对应的接口类型,才能使用Lambda作为该接口的实例。个人理解:对方法的描述(定义)进行了一个简化
基础语法:
语法格式1:无参数,无返回值 ()->System.out.println(‘hello Lambda!’)
// 原来的写法 @Test public void test1(){ int num = 1; Runnable runnable = new Runnable() { @Override public void run() { System.out.println("print : " + num); } }; runnable.run(); } // Lambda写法 @Test public void test2(){ int num = 1; Runnable runnable = () ->{ System.out.println("语法格式一:无参数,无返回值"); System.out.println("print : " + num); }; runnable.run(); }语法格式2:有一个参数,无返回值 (x)->System.out.println(x);
语法格式3:若只有一个参数,小括号可以省略不写 x->System.out.println(x);
@Test public void test3(){ Consumer<String> consumer = (x)->System.out.println(x); consumer.accept("有一个参数,无返回值"); Consumer<String> consumer2 = x->System.out.println(x); consumer2.accept("若只有一个参数,小括号可以省略不写"); }语法格式4:有两个以上的参数,有返回值,并且Lambda体中有多条语句
@Test public void test4() { Comparator<Integer> comparator = (x,y)->{ System.out.println("函数式接口"); return Integer.compare(x,y); }; Set set = new TreeSet(comparator); set.add(3); set.add(9); set.add(7); set.add(6); set.add(2); set.add(5); System.out.println(set); }语法格式5:若Lambda体只有一条语句,return 和大括号都可以省略不写
语法格式6:Lambda表达式的参数列表的数据类型可以省略不写,因为JVM编译器通过上下文推断出数据类型,即类型推断
@Test public void test5() { Comparator<Integer> comparator = (x,y)->Integer.compare(x,y); Set set = new TreeSet(comparator); set.add(3); set.add(9); set.add(7); set.add(6); set.add(2); set.add(5); System.out.println(set); }**总结:**上联:左右遇一括号省 下联:左侧推断类型省 横批:能省则省
函数式接口
接口中只有一个抽象方法的接口,称为函数式接口,可以使用注解@FunctionalInterface装饰,可以检查是否是函数式接口

三、jdk8 内置四大核心函数接口
消费型接口(海王式接口,只知道索取)
Consumer
:消费型接口 void accept(T t);
至于具体怎么消费(使用),需要自定义
@Test public void test1(){ // consumer.accept(money); 有一个参数 happy(300,(m)-> System.out.println("大保健真嗨皮,每次消费:"+m+"元")); } public void happy(double money, Consumer<Double> consumer){ consumer.accept(money); }andThen:
Consumer接口的默认方法andThen
作用:需要两个Consumer接口,可以把两个Consumer接口组合到一起,在对数据进行消费public class AndThen { public static void method(String s, Consumer<String> consumer1,Consumer<String> consumer2){ // consumer1.accept(s); // consumer2.accept(s); //使用andThen方法,把两个Consumer接口连接到一起,在消费数据 //con1连接con2,先执行con1消费数据,在执行con2消费数据 consumer1.andThen(consumer2).accept(s); } public static void main(String[] args) { method("Hello", (t)-> System.out.println(t.toUpperCase()), //消费方式:把字符串转换为大写输出 (t)-> System.out.println(t.toLowerCase()));//消费方式:把字符串转换为小写输出 method("Hello", new Consumer<String>() { @Override public void accept(String s) { System.out.println(s.toUpperCase()); }},new Consumer<String>() { @Override public void accept(String s1) { System.out.println(s1.toUpperCase()); } }); } }供给型接口(舔狗式接口,只知道付出,不索取回报的)
Supplier
:供给型接口 T get();
Supplier
接口被称之为生产型接口,指定接口的泛型是什么类型,那么接口中的get方法就会生产什么类型的数据 @Test public void test2(){ // supplier.get() 没有参数 List<Integer> list = randomInts(10, () -> (int) (Math.random() * 100)); for (Integer i : list) { System.out.println(i); } System.out.println("====================================================="); List<String> strList = randomStrs(10, () -> UUID.randomUUID().toString().replaceAll("-","")); for (String s : strList) { System.out.println(s); } } // 产生10个随机的整数 public List<Integer> randomInts(int n, Supplier<Integer> supplier){ List<Integer> list = new ArrayList<>(); for (int i = 0; i < n; i++) { list.add(supplier.get()); } return list; } // 产生10个随机的字符串 public List<String> randomStrs(int n, Supplier<String> supplier){ List<String> list = new ArrayList<>(); for (int i = 0; i < n; i++) { list.add(supplier.get()); } return list; }函数型接口(双向奔赴,有输入有输出)
Function
:函数型接口 接口用来根据一个类型的数据得到另一个类型的数据,
前者称为前置条件,后者称为后置条件R apply(T t); Function接口中最主要的抽象方法为:R apply(T t),根据类型T的参数获取类型R的结果。
@Test public void test3(){ String s = "\t\thello world\t\t!"; String s1 = strHandle(s, (str) -> str.trim()); System.out.println("去空格:"+s1); System.out.println("====================================================="); String s2 = strHandle(s, (str) -> str.substring(1)); System.out.println("从第2位开始截取:"+s2); System.out.println("====================================================="); System.out.println(employeeHandle("zhangsan", (name) -> new Employee(name, 22, 6666.6f))); System.out.println("====================================================="); System.out.println(employeeHandle("lisi", (name) -> new Employee(name, 22, 6666.6f))); } // 将对应的字符串做任意的处理 public String strHandle(String s, Function<String,String> function){ return function.apply(s); } // 获取指定姓名的Employee对象 public Employee employeeHandle(String name,Function<String,Employee> function){ return function.apply(name); }断言型接口
Predicate
接口 作用:对某种数据类型的数据进行判断,结果返回一个boolean值
Predicate接口中包含一个抽象方法:
boolean test(T t):用来对指定数据类型数据进行判断的方法
结果:
符合条件,返回true
不符合条件,返回false@Test public void test4(){ List<String> list = Arrays.asList("hello", "hehehe", "heiheihei", "haha", "wuwu", "enen", "yiyiyi"); // 集合中小于6的字符串 List<String> len_lt6 = filterStrs(list, (s) -> s.length() < 6); for (String s : len_lt6) { System.out.println(s); } System.out.println("====================================================="); // 集合中包含"he"的字符串 List<String> include_he = filterStrs(list, (s) -> s.contains("he")); for (String s : include_he) { System.out.println(s); } } // 对集合中的字符串进行某种规则的过滤 public List<String> filterStrs(List<String> strs, Predicate<String> predicate){ List<String> list = new ArrayList<>(); for (String str : strs) { if (predicate.test(str)){ list.add(str); } } return list; }**注意:**使用匿名内部类会编译后会多产生一个类,而使用lambda,底层是invokedynamic指令,不会有多余的类
四、关于jdk8的对象引用问题
若Lambda体中的内容有方法已经实现了,我们可以使用“方法引用”(可以理解为方法引用是Lambda表达式的另一种表现形式)
主要有三种语法格式
对象::实例方法名
类::静态方法名
类::实例方法名@Test public void test1(){ Consumer c1 = (x)->System.out.println(x); Consumer c2 = System.out::println; PrintStream printStream = System.out; Consumer c3 = printStream::println; }注意
1、Lambda体中调用方法的参数列表与返回值类型,要与函数式接口中抽象方法的函数列表和返回值类型保持一致! 2、若Lambda参数列表中的第一参数是 实例方法的调用者,而第二个参数是实例方法的参数时,可以使用ClassName::method
@Test public void test2(){ BiPredicate<String,String> biPredicate = (x,y)->x.equals(y); BiPredicate<String,String> biPredicate2 = String::equals; }构造引用
格式:ClassName::new 注意:需要调用的构造器的参数列表要与函数式接口中的抽象方法的参数列表保持一致!
// 无构造参数的情况 @Test public void test3(){ Supplier<Employee> supplier = ()->new Employee(); Supplier<Employee> supplier2 = Employee::new; System.out.println(supplier.get()); System.out.println(supplier2.get()); } // 一个构造参数的情况,类型推断 @Test public void test4(){ Function<String,Employee> function = (name)->new Employee(name); Function<String,Employee> function2 = Employee::new; System.out.println(function.apply("zhangsan")); System.out.println(function2.apply("zhangsan")); }数组引用
格式:Type[]::new
@Test public void test5(){ Function<Integer,String[]> function = (n)->new String[n]; Function<Integer,String[]> function2 =String[]::new; System.out.println(function.apply(10).length); System.out.println(function2.apply(20).length); }
五、StreamAPI
流是数据渠道,用于操作数据源(集合、数组等)生成的元素序列。
Stream(流)是一个来自数据源的元素队列
- 元素是特定类型的对象,形成一个队列。
- 数据源流的来源。 可以是集合,数组等。
- Stream自己不会存储元素,而是按需计算。
- Stream不会改变源对象,并且能返回一个持有结果的新流
- Stream操作是延迟操作,意味着他们会等到需要结果的时候才执行
和以前的Collection操作不同, Stream操作还有两个基础的特征:
- Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent
style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。- 内部迭代: 以前对集合遍历都是通过Iterator或者增强for的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式,流可以直接调用遍历方法。
Stream的操作三个步骤
创建Stream 一个数据源(如:集合、数组),获取一个流
中间操作 一个中间操作链,对数据源的数据进行处理
终止操作(终端操作) 一个终止操作,执行中间操作链,并产生结
5.1 Stream流的五种实例化方式
创建Stream:
对象.stream();
Arrays.stream(…);
Stream.of(…);
Stream.iterate(…);
Stream.generate(…);
@Test public void test1(){ List list=new ArrayList(); Stream stream = list.stream(); Employee[] employees = new Employee[10]; Stream<Employee> stream1 = Arrays.stream(employees); Stream<String> stream2 = Stream.of("aa", "bb", "cc"); // 创建无限流 Stream<Integer> stream3 = Stream.iterate(6, (x) -> x + 2); stream3.limit(20).forEach(System.out::println); System.out.println("==========================================================="); Stream<Integer> stream4 = Stream.generate(() -> (int) (Math.random() * 100)); stream4.limit(20).forEach(System.out::println); }5.2 Stream流处理的filter过滤操作和distinct操作
中间操作
filter:接收Lambda,从流中排除某些元素。
limit:截断流,使其元素不超过给定数量。
skip:跳过元素,返回一个扔掉了前n个元素的流。若流中元素不足n个,返回一个空流。与limit互补。
distinct:筛选,通过流所生成元素的hashCode和equals去除重复元素
List<Employee> employees; @Before public void before(){ employees = Arrays.asList(new Employee("zhangsan",22,8888.8f), new Employee("lisi",44,6666.6f), new Employee("wangwu",55,4444.4f), new Employee("maliu",11,1111.1f), new Employee("tianqi",77,7777.7f), new Employee("wangba",33 ,3333.3f), new Employee("zhaojiu",99,5656.7f), new Employee("huoying",56,8787.6f)); } // filter过滤操作 @Test public void test2(){ Stream<Employee> stream = employees.stream().filter((e) -> { System.out.println("过滤出薪资大于6000的员工"); return e.getSalary() > 6000; }).limit(3); System.out.println("=========惰性求值============="); stream.forEach(System.out::println); } // limit与skip过滤操作 @Test public void test3(){ employees.stream().forEach(System.out::println); System.out.println("================================"); employees.stream().limit(3).forEach(System.out::println); System.out.println("================================"); employees.stream().skip(3).forEach(System.out::println); } // distinct:筛选,通过流所生成元素的hashCode和equals去除重复元素 @Test public void test4(){ // new Employee("zhaojiu",99,5656.7f) List employees2 = new ArrayList(); employees2.addAll(employees); System.out.println("目前集合的长度:"+employees2.size()); employees2.add(new Employee("zhaojiu",99,5656.7f)); System.out.println("添加名字相同元素后集合的长度:"+employees2.size()); // 重写hashCode和equals方法,发现distinct可以去重掉新增的元素 employees2.stream().distinct().forEach(System.out::println); } }过滤:filter 可以通过 filter 方法将一个流转换成另一个子集流
5.3 Stream流处理之map映射问题
map:接收Lambda,将元素转换成其他形式或提取信息,接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素;
flatMap:接受一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流
@Test public void test5() { List<String> list = Arrays.asList("aaa", "bbb", "ccc", "ddd", "eee"); list.stream().map((s) -> s.toUpperCase()).forEach(System.out::println); System.out.println("================================"); employees.stream().map((x) -> x.getName()).forEach(System.out::println); System.out.println("================================"); employees.stream().map(Employee::getName).forEach(System.out::println); } @Test public void test6() { List<String> teamIndia = Arrays.asList("Virat", "Dhoni", "Jadeja"); List<String> teamAustralia = Arrays.asList("Warner", "Watson", "Smith"); List<String> teamEngland = Arrays.asList("Alex", "Bell", "Broad"); List<String> teamNewZeland = Arrays.asList("Kane", "Nathan", "Vettori"); List<String> teamSouthAfrica = Arrays.asList("AB", "Amla", "Faf"); List<String> teamWestIndies = Arrays.asList("Sammy", "Gayle", "Narine"); List<String> teamSriLanka = Arrays.asList("Mahela", "Sanga", "Dilshan"); List<String> teamPakistan = Arrays.asList("Misbah", "Afridi", "Shehzad"); List<List<String>> playersInWorldCup2016 = new ArrayList<>(); playersInWorldCup2016.add(teamIndia); playersInWorldCup2016.add(teamAustralia); playersInWorldCup2016.add(teamEngland); playersInWorldCup2016.add(teamNewZeland); playersInWorldCup2016.add(teamSouthAfrica); playersInWorldCup2016.add(teamWestIndies); playersInWorldCup2016.add(teamSriLanka); playersInWorldCup2016.add(teamPakistan); // Let's print all players before Java 8 List<String> listOfAllPlayers = new ArrayList<>(); for(List<String> team : playersInWorldCup2016){ for(String name : team){ listOfAllPlayers.add(name); } } System.out.println("Players playing in world cup 2016"); System.out.println(listOfAllPlayers); // Now let's do this in Java 8 using FlatMap List<String> flatMapList = playersInWorldCup2016.stream() .flatMap(pList -> pList.stream()) .collect(Collectors.toList()); System.out.println("List of all Players using Java 8"); System.out.println(flatMapList); List<Stream<String>> flatMapList2 = playersInWorldCup2016.stream() .map(pList -> pList.stream()) .collect(Collectors.toList()); System.out.println("List of all Players using Java 8"); System.out.println(flatMapList2); }map与flatMap的区别就好比集合中的add与addAll的区别
5.4 Stream流处理之查找与匹配
排序
sorted:自然排序(Comparable)
sorted(Comparator com):定制排序(Comparator)
@Test public void test7() { // java.lang.ClassCastException: com.javaxl.lambda.Employee cannot be cast to java.lang.Comparable // implements Comparable<Employee>重写方法让其按年龄排序 employees.stream().sorted().forEach(System.out::println); System.out.println("================================"); // 自然排序接口排序 employees.stream().sorted((x,y)->-Integer.compare(x.getAge(),y.getAge())).forEach(System.out::println); }查找与匹配
allMatch:检查是否匹配所有元素 anyMatch:检查是否至少匹配一个元素
noneMatch:检查是否没有匹配所有元素 findFirst:返回第一个元素
findAny:返回当前流中的任意元素 count:返回流中元素的总个数
max:返回流中最大值 min:返回流中最小值
5.5 Stream流处理之归约map-reduce模式
终止操作
一个终止操作,执行中间操作链,并产生结果
**备注:**map和reduce的连接通常称为map-reduce模式,因Google用它来进行网络搜索而出名。
归约
T reduce(T identity, BinaryOperator
accumulator); 可以将流中元素反复结合起来,得到一个值,返回T; Optional
reduce(BinaryOperator accumulator); 可以将流中元素反复结合起来,得到一个值,返回Optional ; import java.util.stream.Stream; /** * Created by hongcaixia on 2019/10/31. */ public class StreamReduce { public static void main(String[] args) { sum(1,2,3,4,5); } private static void sum(Integer... nums){ Stream.of(nums).reduce(Integer::sum).ifPresent(System.out::println); } } @Test public void test10() { List<Integer> list = Arrays.asList(1,2,3,4,5); Integer sum = list.stream().reduce(0,(x,y)->x+y); System.out.println(sum); }
5.6 Stream流处理之Collect基本概念及求值运算
收集
collect(Collector c) 将流转换为其他形式。接收一个Collector接口的实现,用于给Stream中元素做汇总的方法;
Collector接口中方法的实现决定了如何对流执行收集操作(如收集到List、Set、Map)
但是Collectors实现类提供了很多静态方法,可以方便地创建常见收集器实例;
@Test public void test2(){ List<String> list = managers.stream().map(Manager::getName).collect(Collectors.toList()); for (String s : list) { System.out.println(s); } System.out.println("================================"); Set<String> set = managers.stream().map(Manager::getName).collect(Collectors.toSet()); for (String s : set) { System.out.println(s); } System.out.println("================================"); HashSet<String> hashSet = managers.stream().map(Manager::getName).collect(Collectors.toCollection(HashSet::new)); for (String s : hashSet) { System.out.println(s); } } @Test public void test3() { // 个数 System.out.println(managers.stream().collect(Collectors.counting()).toString()); // 平均值 System.out.println(managers.stream().collect(Collectors.averagingDouble((Manager::getSalary))).toString()); // 求和 System.out.println(managers.stream().collect(Collectors.summingDouble(Manager::getSalary)).toString()); // 最大值 System.out.println(managers.stream().collect(Collectors.maxBy(Manager::compareTo))); }
5.7 Stream流处理之Collect分组分区处理
多级分组
@Test public void test4() { Map<Manager.Status, Map<String, List<Manager>>> map = managers.stream().collect(Collectors.groupingBy(Manager::getStatus, Collectors.groupingBy((m) -> { if (((Manager) m).getAge() < 35) { return "青年"; } else if (((Manager) m).getAge() > 55) { return "老年"; } else { return "中年"; } }))); System.out.println(map); }分区
@Test public void test5() { Map<Boolean, List<Manager>> map = managers.stream().collect(Collectors.partitioningBy((m) -> m.getSalary() > 6000)); for (Map.Entry<Boolean, List<Manager>> entry : map.entrySet()) { System.out.println(entry.getKey() + ":" + entry.getValue()); } }元素汇总
@Test public void test6() { // DoubleSummaryStatistics{count=8, sum=46666.199829, min=1111.099976, average=5833.274979, max=8888.799805} DoubleSummaryStatistics collect = managers.stream().collect(Collectors.summarizingDouble(Manager::getSalary)); System.out.println(collect.getCount()); System.out.println(collect.getAverage()); System.out.println(collect.getMax()); System.out.println(collect.getMin()); System.out.println(collect.getSum()); }
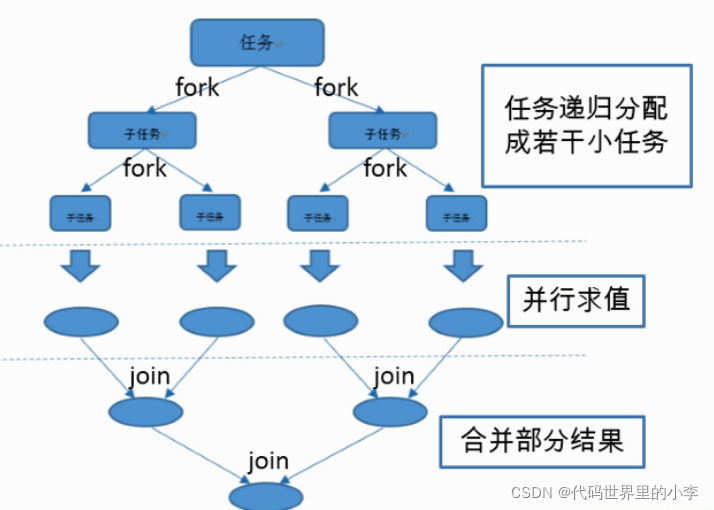
5.8 并行流和顺序流
并行流是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
通过parallel()与sequential()可以实现并行流和顺序流之间的切换。
Fork/Join框架:在必要的情况下,将一个大任务进行拆分(fork)成若干小任务(拆到不可再拆时),再将一个个小任务运算的结果进行join汇总。
@Test public void test12() { //顺序流 LongStream.rangeClosed(0,100).reduce(0,Long::sum); //并行流 long reduce = LongStream.rangeClosed(0, 100).parallel().reduce(0, Long::sum); //5050 System.out.println(reduce); }
六.Optional容器类
Optional
类(java.util.Optional)是一个容器类,代表一个值存在或不存在,原来用null表示一个值不存在,现在Optional可以更好的表达这个概念。并且可以避免空指针异常。 Optional.of:创建一个容器实例
Optional.ofNullable:创建一个容器实例(推荐)
orElse:获取容器内部元素,没有元素返回默认值
orElseGet:获取容器内部元素,没有元素返回默认值(推荐)
map:如果有值对其处理,并返回处理后的Optional,否则返回Optional.empty();
flatMap:与map类似,返回的对象必须是Optional
@Test public void test1(){ // 这个依然会空指针 // Optional<Boolean> aBoolean = Optional.of(null); // 这个不会创建空实例 Optional<Boolean> aBoolean = Optional.ofNullable(null); if (aBoolean.isPresent()){ System.out.println(aBoolean.get()); } // Optional<Manager> op = Optional.ofNullable(new Manager("lisi", 44, 6666.6f, Manager.Status.FREE)); Optional<Manager> op = Optional.ofNullable(null); // Manager manager = op.orElse(new Manager()); Manager manager = op.orElseGet(()->{ System.out.println("orElse与orElseGet,这个可以做中间处理"); return new Manager(); }); System.out.println(manager); } @Test public void test2(){ Optional<Manager> op = Optional.ofNullable(new Manager("lisi", 44, 6666.6f, Manager.Status.FREE)); System.out.println(op.map(Manager::getName)); System.out.println(op.flatMap((e)->Optional.ofNullable(e.getName()))); }下面例子论证Optional解决空指针问题
原有的非空判断,层级机构太深,代码冗余
相关实体类
public class Girl { private String name; @Override public String toString() { return "Girl{" + "name='" + name + '\'' + '}'; } public Girl() { } public Girl(String name) { this.name = name; } public String getName() { return name; } public void setName(String name) { this.name = name; } } public class Boy { private Girl girl; public Girl getGirl() { return girl; } public void setGirl(Girl girl) { this.girl = girl; } public Boy() { } public Boy(Girl girl) { this.girl = girl; } } public class BoyNew { private Optional<Girl> girl = Optional.empty(); public Optional<Girl> getGirl() { return girl; } public void setGirl(Optional<Girl> girl) { this.girl = girl; } public BoyNew() { } public BoyNew(Optional<Girl> girl) { this.girl = girl; } }测试代码论证
@Test public void test3(){ Boy boy = new Boy(); System.out.println("女朋友是:"+getGirlName(boy)); Boy boy2 = new Boy(new Girl("玛利亚")); System.out.println("女朋友是:"+getGirlName(boy2)); BoyNew boyNew = new BoyNew(); System.out.println("女朋友是:"+getGirlName2(boyNew)); BoyNew boyNew2 = new BoyNew(Optional.ofNullable(new Girl("松岛"))); System.out.println("女朋友是:"+getGirlName2(boyNew2)); } public String getGirlName2(BoyNew boy){ return Optional.ofNullable(boy) .orElse(new BoyNew()) .getGirl() .orElse(new Girl("波多")) .getName(); } public String getGirlName(Boy boy){ if (boy !=null){ Girl girl = boy.getGirl(); if(girl!=null){ return girl.getName(); } } return "波多"; }
七.日期时间LocalDateTime
具体的可以查看这篇博客 JDK8新特性(五):JDK8时间日期API_扛麻袋的少年的博客-CSDN博客_jdk8 时间新特性
@Test public void test4(){ LocalDate localDate = LocalDate.now(); System.out.println(localDate); LocalTime localTime = LocalTime.now(); System.out.println(localTime); LocalDateTime localDateTime = LocalDateTime.now(); System.out.println(localDateTime); System.out.println(localDateTime.getYear()); System.out.println(localDateTime.getMonthValue()); System.out.println(localDateTime.getDayOfMonth()); System.out.println(localDateTime.getHour()); System.out.println(localDateTime.getMinute()); System.out.println(localDateTime.getSecond()); } @Test public void test5(){ LocalDateTime localDateTime = LocalDateTime.now(); DateTimeFormatter sdf = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"); System.out.println(sdf.format(localDateTime)); }

评论区